回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
我本将心向明月,奈何明月照沟渠。
大家好,我是Python进阶者。
一、前言
前几天在Python星耀交流群有个叫【蒋卫涛】的粉丝问了一个Python自动化办公的题目,这里拿出来给大家分享。
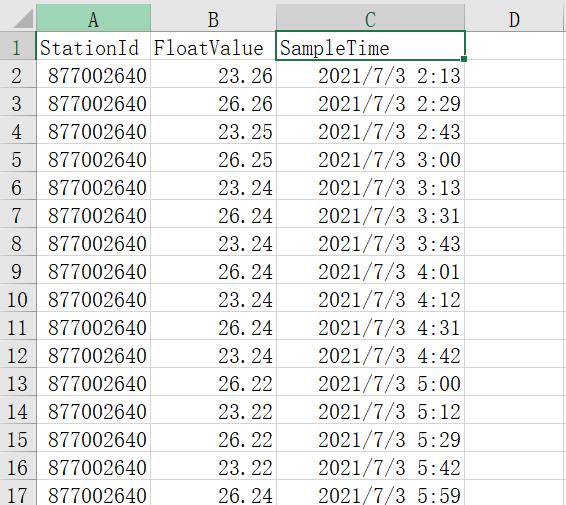
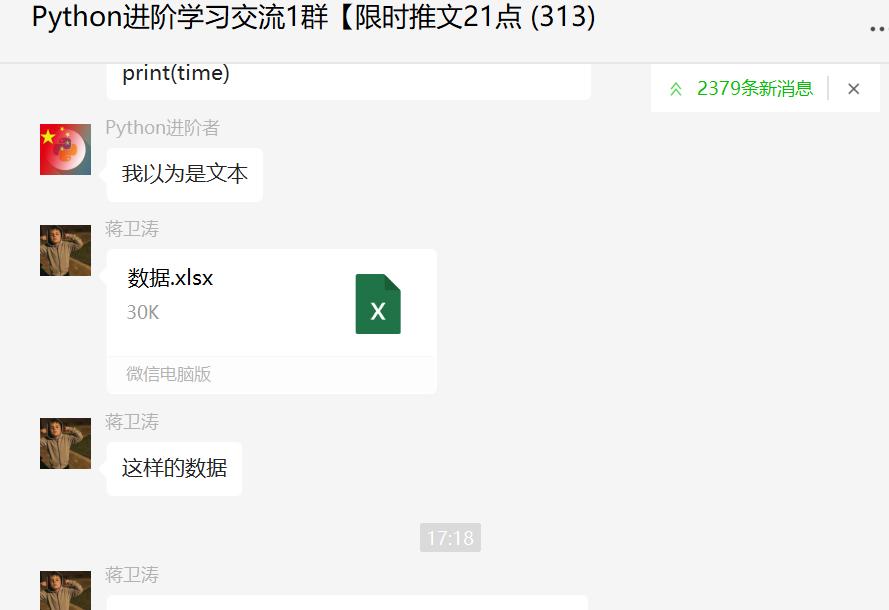 下面是他的原始数据。
下面是他的原始数据。
 二、实现过程
二、实现过程
这里【月神】、【瑜亮老师】分别给出了5种可行的方法,分享给大家。
方法一:分别取日期与小时,按照日期和小时删除重复项importpandasaspdexcel_filename=’数据.xlsx’df=pd.read_excel(excel_filename)#print(df)#方法一:分别取日期与小时,按照日期和小时删除重复项df[‘day’]=df[‘SampleTime’].dt.day#提取日期列df[‘hour’]=df[‘SampleTime’].dt.hour#提取小时列df=df.drop_duplicates(subset=[‘day’,’hour’])#删除重复项#把筛选结果保存为excel文件df.to_excel(‘数据筛选结果2.xlsx’)方法二:把日期中的分秒替换为0importpandasaspdexcel_filename=’数据.xlsx’df=pd.read_excel(excel_filename)#方法二:把日期中的分秒替换为0SampleTime_new=df[‘SampleTime’].map(lambdax:x.replace(minute=0,second=0))data=df[SampleTime_new.duplicated()==False]print(df)#把筛选结果保存为excel文件df.to_excel(‘数据筛选结果2.xlsx’)方法三:对日期时间按照小时进行分辨importpandasaspdexcel_filename=’数据.xlsx’df=pd.read_excel(excel_filename)#方法三:对日期时间按照小时进行分辨SampleTime_new=df[‘SampleTime’].dt.floor(freq=’H’)df=df[SampleTime_new.duplicated()==False]print(df)#把筛选结果保存为excel文件df.to_excel(‘数据筛选结果2.xlsx’)方法四:对日期时间按照小时进行分辨importpandasaspdexcel_filename=’数据.xlsx’df=pd.read_excel(excel_filename)#方法四:对日期时间按照小时进行分辨SampleTime_new=df[‘SampleTime’].dt.to_period(freq=’H’)df=df[SampleTime_new.duplicated()==False]print(df)#把筛选结果保存为excel文件df.to_excel(‘数据筛选结果2.xlsx’)方法五:对日期时间进行重新格式,并按照新的日期时间删除importpandasaspdexcel_filename=’数据.xlsx’df=pd.read_excel(excel_filename)#方法五:对日期时间进行重新格式,并按照新的日期时间删除重复项(会引入新列)df[‘new’]=df[‘SampleTime’].dt.strftime(‘%Y-%m-%d%H’)df=df.drop_duplicates(subset=[‘new’])print(df)#把筛选结果保存为excel文件df.to_excel(‘数据筛选结果2.xlsx’)小总结
前面这5个方法有相似的地方,比如方法1和方法5都是把日期只取到小时,方法3和方法4都是按照小时进行分辨,而方法1,2和5其实本质上都是把分钟和秒变成0,比如方法5中这样写的话,就和方法2是一样的df[‘new’] = df[‘SampleTime’].dt.strftime(‘%Y-%m-%d %H:00:00’)
方法2和3是【月神】提供的方法,方法1,4,5是【瑜亮老师】提供的方法。
【月神】使用了floor向下取整,也就是抹去零头。本来【瑜亮老师】还想用ceil向上取整试试,结果发现不对,整点的会因为向上取整而导致数据缺失,比如8:15,向上取整就是9点,如果同一天中刚好9:00也有一条数据,那么这个9点的数据就会作为重复的数据而删除。本来应该是8点9点各取1条数据的,结果变成了只取8点这1条。包括round,也会因为四舍五入(这里就不纠结了)导致信息缺失更多。
方法六:使用openpyxl处理
这里我本来还想用openpyxl进行实现,但是却卡壳了,只能提取出24条数据出来,先放这里做个记录吧,哪天突然间灵光了,再补充好了。
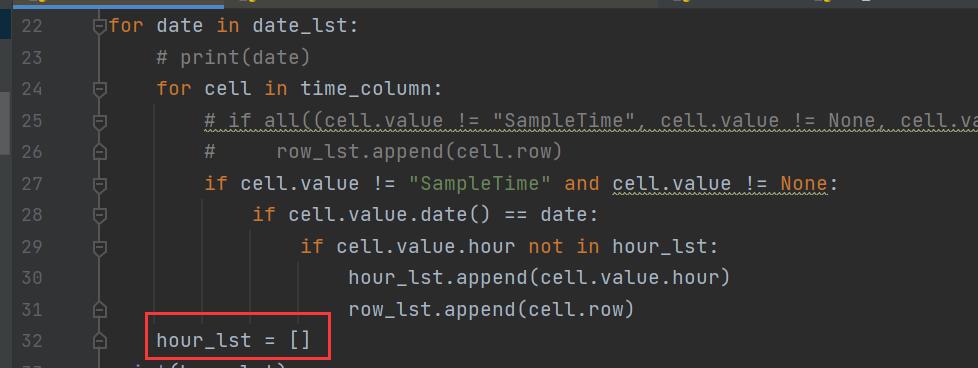
fromopenpyxlimportload_workbook,Workbookfromdatetimeimportdatetime#打开数据工作簿workbook=load_workbook(‘数据.xlsx’)#打开工作表sheet=workbook.activetime_column=sheet[‘C’]row_lst=[]date_lst=[]hour_lst=[]forcellintime_column:ifcell.value!=”SampleTime”andcell.value!=None:#print(cell.value.date())ifcell.value.date()notindate_lst:date_lst.append(cell.value.date())#row_lst.append(cell.row)print(date_lst)#ifall(cell.value!=”SampleTime”,cell.value!=None,cell.value.date()==date,cell.value.hournotinhour_lst):fordateindate_lst:#print(date)forcellintime_column:#ifall((cell.value!=”SampleTime”,cell.value!=None,cell.value.date()==date,cell.value.hournotinhour_lst)):#row_lst.append(cell.row)ifcell.value!=”SampleTime”andcell.value!=None:ifcell.value.date()==date:ifcell.value.hournotinhour_lst:hour_lst.append(cell.value.hour)row_lst.append(cell.row)hour_lst=[]print(hour_lst)#将满足要求的数据写入到新表new_workbook=Workbook()new_sheet=new_workbook.active#创建和原数据一样的表头(第一行)header=sheet[1]header_lst=[]forcellinheader:header_lst.append(cell.value)new_sheet.append(header_lst)#从旧表中根据行号提取符合条件的行,并遍历单元格获取值,以列表形式写入新表forrowinrow_lst:data_lst=[]forcellinsheet[row]:data_lst.append(cell.value)new_sheet.append(data_lst)#最后切记保存new_workbook.save(‘新表.xlsx’)print(“满足条件的新表保存完成!”)
这个方法就是遍历date,然后遍历一次之后,将hour置空,如此反复,这样就可以每次取到每天唯一的某一个小时的一个时间。
 三、总结
三、总结
大家好,我是Python进阶者。这篇文章主要分享了使用Pandas从Excel文件中提取满足条件的数据并生成新的文件的干货内容,文中提供了5个方法,行之有效。如果你还有其他写法,也欢迎大家积极尝试,一起学习,成功的话记得分享给我噢!
最后感谢粉丝【蒋卫涛】提问,感谢【月神】、【瑜亮老师】给出的代码和具体解析,感谢粉丝【dcpeng】、【冯诚】、【艾希·觉罗】、【多隆】、【憶?? 逍遥】、【问题不大】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何Python问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。