机器之心原创
本文是一篇关于神经网络压缩领域的论文解读,通过对ICCV 2019中的三篇论文进行分析,读者可以了解目前的发展趋势。
神经网络压缩方向是目前深度学习研究的一个热门的方向,其主要的研究方向是压缩,蒸馏,网络架构搜索,量化等。在 ICCV2019 中,不少的研究单位和学者都发表了神经网络压缩方向的论文。本文主要以其中三篇论文来研究神经网络压缩的目前发展趋势。
论文 1:基于元学习的模型压缩《MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning》
1 论文主旨概述
Meta learning 论文是旷世研究院提出的一种神经网络压缩方法。通道剪枝 [1] 作为一种神经网络的压缩方法被广泛的实现和应用,一般剪枝算法通过对预训练的大网络裁剪次要的通道,之后微调,得到最终的剪枝网络。随着 AutoML[2] 的发展,metapruning 利用 autoML 的自动寻找最优结构的特点,脱离了人工设计的局限以及弥补剪枝算法的依赖数据的不足。本文从元学习的角度出发,直接用元学习得到剪枝网络(pruned networks)的结构以及自生成权重,而不是保留原始网络的重要参数。
2 方法:
近年来,有研究 [3] 表明无论是否保存了原始网络的权值,剪枝网络都可以达到一个和原始网络相同的准确率。因此,通道剪枝的本质是逐层的通道数量,也就是网络结构。鉴于此项研究,Metapruning 决定直接保留裁剪好的通道结构,区别于剪枝的裁剪哪些通道。
本文提出来一个 Meta network,名为 PruningNet,可以生成所有候选的剪枝网络的权重,并直接在验证集上评估,有效的搜索最佳结构。
Pruningnet training
PruningNet 是一个 meta network,以一组网络编码向量 (c1,c2,,,cl) 为输入,输出为剪枝网络的权重。一个 PruningNet 的训练方式如下图 (1) 所示:
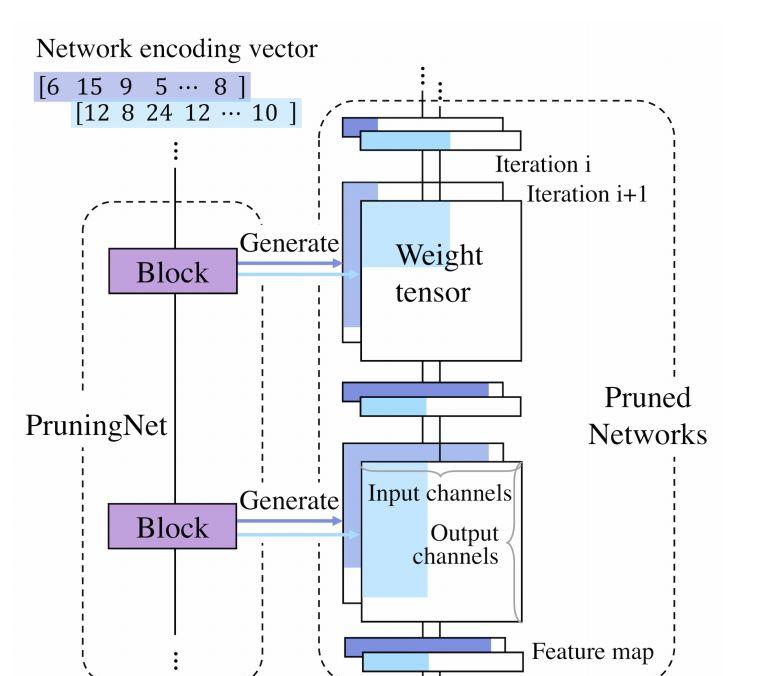 图(1)PruningNet 的随机训练方法
图(1)PruningNet 的随机训练方法
图 (1) 中,PruningNet 由多个 block 组成,其中的每个 block 由两个全连接层组成。
在前向过程中,PruningNet 以网络编码向量(即剪枝网络的每层通道数)为输入,生成权重矩阵。同时,剪枝网络以网络编码向量中的数值为输出通道,并将生成的权重矩阵裁剪匹配剪枝网络的输入输出。对于一个 batach 的输入图像,我们可以计算带权重的剪枝网络的前向损失。
在反向过程中,本文并不是更新剪枝网络的权重,而是计算 PruningNet 的梯度,更新 PruningNet 的权重(全连接层参数)。在整个训练过程中,由于所有的操作都是可微的,所以能够进行端到端的学习。通过随机生成不同的网络编码向量,可以得到不同的剪枝网络结构。
Pruned-network search-evolutionary algorithm
本文中,网络向量编码为 pruned networks 的基因。在硬约束的前提下,我们首先随机选择大量的基因并获得相关的剪枝网络的准确率。选择前 top k 的基因,对其做变异和交叉,生成新的基因。同时对不符合要求的基因添加约束来消除。如此迭代数次,最终可以得到既满足约束又获得最高准确率的基因。具体算法如图(2)所示:

图(2)进化搜索算法
3 实验和结果
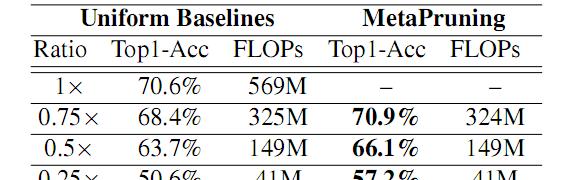 图(3)mobilenetV1 结构实验
图(3)mobilenetV1 结构实验
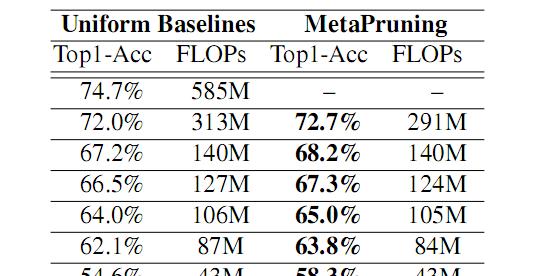 图(4)mobilenet V2 实验图(3)(4)表明 metaPruning 相比较一般基线模型相比,metaPruning 得到的结构在效率和 top1 上都有较大的优势。
图(4)mobilenet V2 实验图(3)(4)表明 metaPruning 相比较一般基线模型相比,metaPruning 得到的结构在效率和 top1 上都有较大的优势。
4 总结
本文提出的 metaPruning 的方法,从本质上来讲属于一种结构搜索的方法。跳出传统剪枝的思路,不仅仅可以去除数据的约束,同时避免了微调的耗时。
该方法将根据不同的约束加入搜索中,灵活调整算法;
可以应对带 short-cut 的网络结构;
端到端的学习十分高效,且无需更新剪枝网络的权重。
但是,这个网络的生成过程中,需要注意以下的几个问题:(1)对训练的硬件要求,PruningNet 和生成的剪枝网络同时在训练过程中,是否带来了较大的 GPU 资源的消耗,导致生成过程较慢。(2)在生成过程中虽说对样本不做要求,但是简单的几个 batch 的样本对模型的影响应该比较大。
参考文献[1] Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning ??lters for ef??cient convnets. arXiv preprint arXiv:1608.08710, 2016.[2] Tien-Ju Yang, Andrew Howard, Bo Chen, Xiao Zhang, Alec Go, Mark Sandler, Vivienne Sze, and Hartwig Adam. Netadapt: Platform-aware neural network adaptation for mobile applications. In Proceedings of the European Conference on Computer Vision (ECCV), pages 285–300, 2018.[3] Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. Rethinking the value of network pruning.arXiv preprint arXiv:1810.05270, 2018.
1 论文概述
通常来说,知识蒸馏需要原始训练数据的参与,才能达到一个较好的蒸馏效果,那么在缺乏原始数据甚至无数据的时候,或者,老师模型只知道接口不知道其模型结构的时候,如何才能达到一个蒸馏的效果呢?此文章的出发点就在此,文章利用 GAN 生成图像的特性来生成蒸馏所需数据。
2 Data-free 网络压缩方法
在神经网络压缩领域,SVD(singular value decomposition)[1],KD(knowledge distillation)[2],基本都是需要数据驱动的,在有原始数据参与的时候能达到一个较好的压缩效果。无需数据驱动的压缩方法较少,比如合并相似单元 [3],但是这些方法的效果并不如数据驱动的方法。
GAN 生成训练样本
网络通常被用与生成样本,包括生成器 G 和辨别器 D。对于一个普通的 GAN 网络而言,给定一个带噪声的向量 z,其损失函数表示为公式(1):
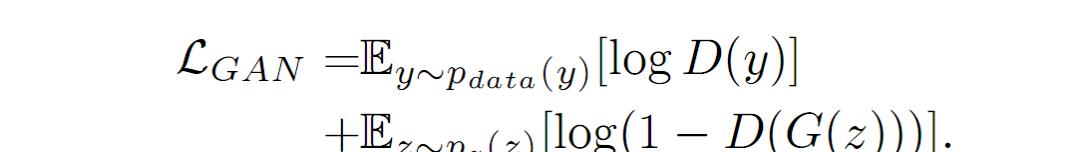 利用公式(1)分别训练 G 和 D。与普通 GAN 网络不同的是,传统 GAN 网络中,D 网络对于输入的图像,其输出是判别真假的二分类。在本文中,我们给定 D 为预训练完成的老师网络,其输出是图像的类别数。为了适应这种情况下的 GAN 网络,本文利用新的损失函数来更新训练 G。具体的公式如下所示:
利用公式(1)分别训练 G 和 D。与普通 GAN 网络不同的是,传统 GAN 网络中,D 网络对于输入的图像,其输出是判别真假的二分类。在本文中,我们给定 D 为预训练完成的老师网络,其输出是图像的类别数。为了适应这种情况下的 GAN 网络,本文利用新的损失函数来更新训练 G。具体的公式如下所示:
其中:(1)Loh 表示 one-hot loss , 此时的 D 网络输出为类别数。假设对一个输入为X={X1,X2,,,Xn} 的图像来说,D 的输出为 {y1,y2,,,yn},根据输出得到的预测的 label 为 {t1,t2,,,tn},Loh 则可以表示为输出和预测值之间的交叉熵损失:
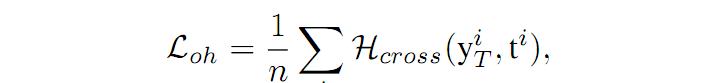 (2)La 表示激活损失,如果一个输入图像是真实的图像而不是随机向量生成的,那么在 D 网络中,经过 D 提取进过全连接层之前得到的输出值 ft,其激活值应该为一个较高的值。所以,La 可以表示为如下的公式:
(2)La 表示激活损失,如果一个输入图像是真实的图像而不是随机向量生成的,那么在 D 网络中,经过 D 提取进过全连接层之前得到的输出值 ft,其激活值应该为一个较高的值。所以,La 可以表示为如下的公式:
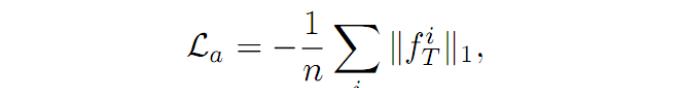 (3)Lie 损失表示的信息熵的大小。用于衡量生成样本中的类别平衡情况。对于给定的输出集合 {y1,y2,,,yn},每个类别的频率分布可以表示为输出的均值。那么 Lie 可以用如下表示:
(3)Lie 损失表示的信息熵的大小。用于衡量生成样本中的类别平衡情况。对于给定的输出集合 {y1,y2,,,yn},每个类别的频率分布可以表示为输出的均值。那么 Lie 可以用如下表示:
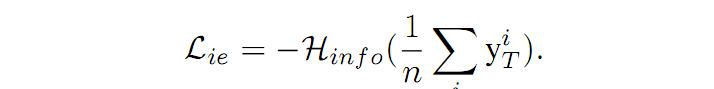
利用 GAN 蒸馏的算法步骤
本文算法主要分为两步:
第一步,训练生成器 G。利用预训练的给定老师模型作为 D,训练生成器 G。
第二步,训练学生网络。利用 G 网络生成训练样本,然后用这些样本来进行知识蒸馏。其蒸馏的示意过程如图(1)所示:
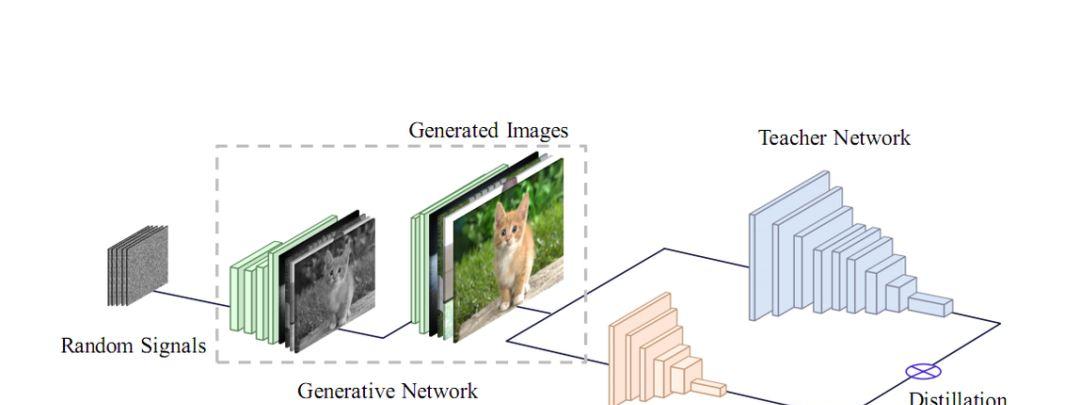 图(1)利用 GAN 的知识蒸馏过程
图(1)利用 GAN 的知识蒸馏过程
3 实验结果
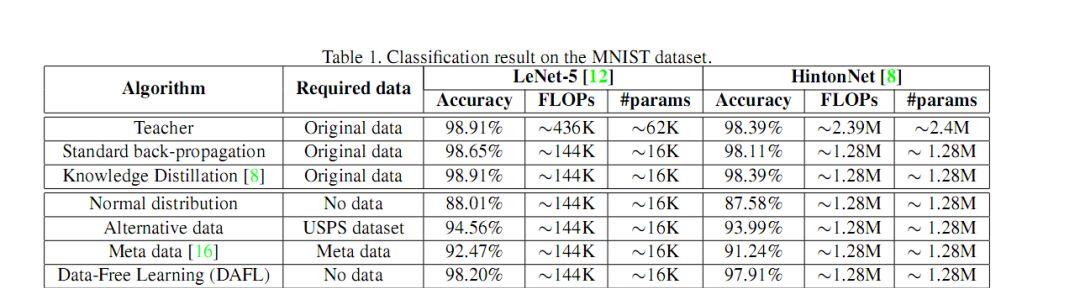 图(2)无数据蒸馏方法在 MNIST 上的实验
图(2)无数据蒸馏方法在 MNIST 上的实验
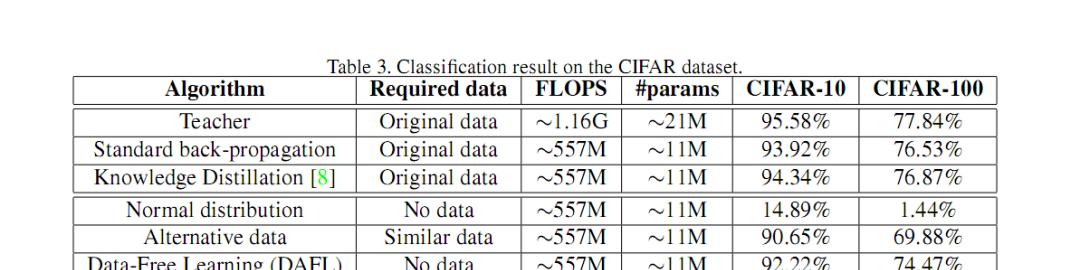 图(3)在 CIFAR 上的实验从图(2)(3)中,我们可以看出无数据的 GAN 蒸馏方法相比较其他无数据的蒸馏方法能够大幅度的提升蒸馏的效果。
图(3)在 CIFAR 上的实验从图(2)(3)中,我们可以看出无数据的 GAN 蒸馏方法相比较其他无数据的蒸馏方法能够大幅度的提升蒸馏的效果。
4 总结
本文从无数据的情况出发,考虑到了蒸馏领域的一个比较常见的情况。本文提出的利用 GAN 的方法新颖且有效,利用 GAN 学习原始数据的分布情况,做到了一个神似而形不似的学习。但是这种 GAN 的生成样本在蒸馏过程中保留了数据的分布,从而在蒸馏中也能达到一个好的效果。但是,这种利用 GAN 的生成数据的方法在笔者看来是不是更适合作为一种数据增强的方式,从训练时间上来看,加入了 G 网络的生成过程,训练过程较长且不太好控制收敛情况。
参考文献
2 Correlation Congruence 知识蒸馏
传统蒸馏定义
传统的蒸馏方法主要是用 kl 散度等距离度量的方法来表征老师网络和学生网络的特征之间的距离,例如公式(1)和(2)所示:
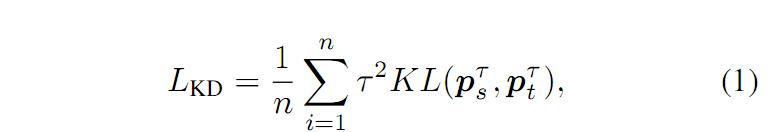
样本间的关系一致性(correlation congruence):
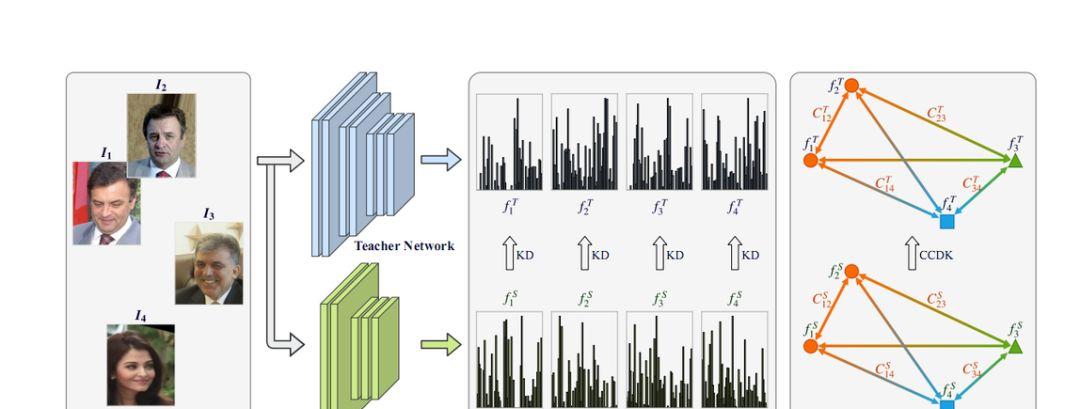 图 1:CCKD 算法图示如图 1 所示,CC(correlation congruence)为图中最右边的部分,表示实例之间的相关性信息,IC(instance congruence)则是实例层的相关信息。我们用 Ft 和 Fs 来分别表示老师学生网络的特征表示的集合。可以用公式表示如下:
图 1:CCKD 算法图示如图 1 所示,CC(correlation congruence)为图中最右边的部分,表示实例之间的相关性信息,IC(instance congruence)则是实例层的相关信息。我们用 Ft 和 Fs 来分别表示老师学生网络的特征表示的集合。可以用公式表示如下:
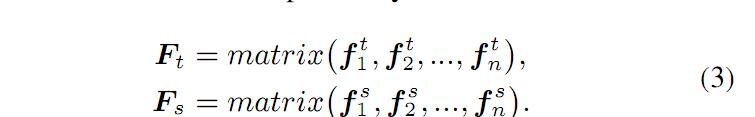 定义 C 为相关性矩阵,其中每一个元素表示 xi 和 yi 的关系,因此可以表示为公式(5):
定义 C 为相关性矩阵,其中每一个元素表示 xi 和 yi 的关系,因此可以表示为公式(5):
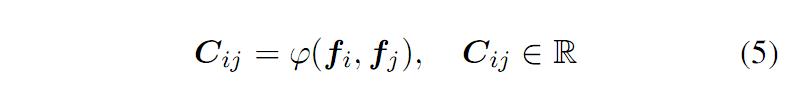 其中,距离度量的方法可以有很多种。基于公式(5),我们可以得到 CCloss。如公式(6)所示:
其中,距离度量的方法可以有很多种。基于公式(5),我们可以得到 CCloss。如公式(6)所示:
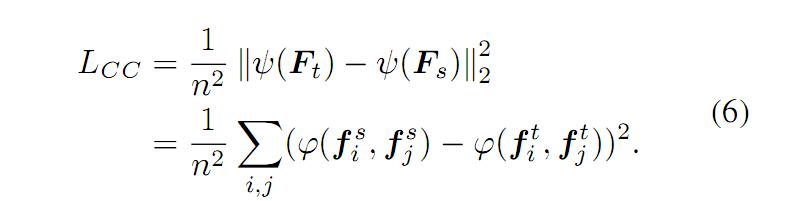
蒸馏算法
CCKD 算法的 loss 由三部分组成,如公式(7)所示:
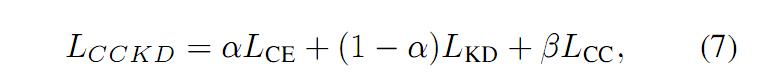 其中 Lce 为交叉熵所示,Lkd 为 t-s 之间的实例层的蒸馏损失,Lcc 则是实例间一致性的损失。
其中 Lce 为交叉熵所示,Lkd 为 t-s 之间的实例层的蒸馏损失,Lcc 则是实例间一致性的损失。
3 实验结果
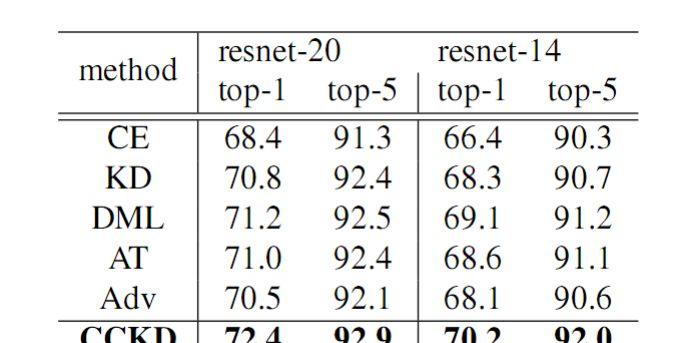 图 2 CCKD 算法在 mnist 的实验
图 2 CCKD 算法在 mnist 的实验
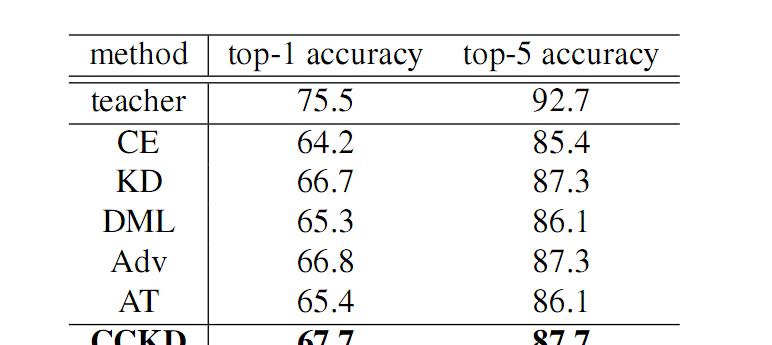 图3 CCKD 算法在 ImageNet1k 的实验
图3 CCKD 算法在 ImageNet1k 的实验
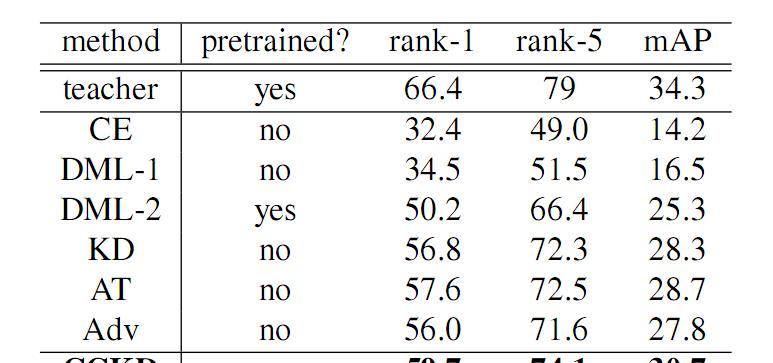 图 4 CCKD 在 MSMT17 的实验
图 4 CCKD 在 MSMT17 的实验
4 总结
在 KD 领域中,[2] 文章也提出来类似的思想,用特征实例之间的距离来做知识蒸馏,就思想上来说并无差异。所以,如果从创新性上来说,本文应该对比同等论文的思想对比。本文在做蒸馏的时候用上了三个损失的结合,做了充分的实验证明算法的有效性。但是,在之后的研究中,三种损失的比重也是一个值得研究的方向。
参考文献

www.jiqizhixin.com/sota