我们会在周末不定期推送一些技术干货。
不上班的清晨,躺在被子里,静静地别人对同一个技术不同的理解,是极好的一件事。
话说,上月云栖大会 · 深圳峰会上,阿里云中间件产品经理凤豪为大家深度介绍了阿里云分布式关系型数据库DRDS的发展历史以及DRDS的优势。

下面是演讲主要内容整理。
1数据库面临的挑战
单机数据库在数据存储容量、访问容量、容灾等方面都会随着业务的增长而到达瓶颈,无论哪一个,对业务来说是一项相当艰巨的挑战。
存储容量瓶颈问题,虽然可以通过在一个机器下面挂很多块磁盘,做到10T、20T、30T容量,然后使用一个MySQL实例支撑,但是数据备份、数据管理(DDL)、数据检索与更新性能(DML)都会出现大幅下滑。
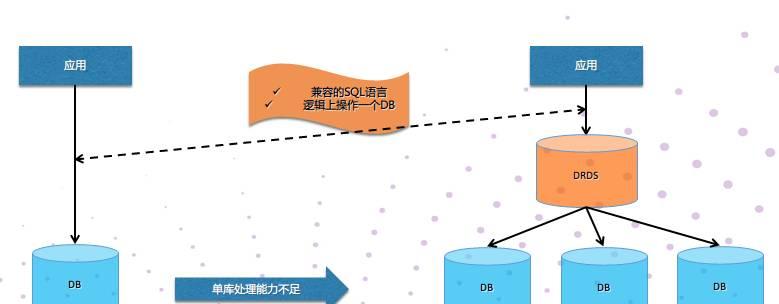
单机数据库的扩展方式通常有两种:通过硬件升级的方式,或者采用分布式的存储方案方式。
但是单机数据库使用分布式架构的同时,缺乏整体的长期的优化和产品化,对应用的侵入性非常大,造成开发和运维的成本大幅提高、降低产品稳定性。
DRDS 成熟的分布式架构,可以提供给用户使用单机数据库一致的体验,底层通过分布式的架构轻松实现数据库的高扩展性,降低开发成本的同时,也提升了数据库存储和服务扩展能力。
数据库的挑战也在于更高的数据容量承载,更高的数据库服务性能支撑。
数据库关键能力在既要保持数据库ACID特性和事务强一致性支持,又要具备无限扩容和弹性扩展的能力。
2DRDS与MySQL、NoSQL的区别
那我们怎么认识DRDS与MySQL、NoSQL之间的差异呢?
具体来说,MySQL核心优势是关系模型ACID特性和事务一致性,但MySQL在保持ACID特性一致性的原则下,单机数据库的扩展给开发和运维带来了巨大的成本。
NOSQL则在抛弃关系模型特性的情况下,通过分布式的方式解决了数据库的高扩展性,但是面对复杂多样的关系模型的使用场景NOSQL不能作为一种通用的数据库解决方案使用,且NOSQL推出的时间短,产品成熟度不高,系统稳定性和可运维行较差,对于正式生产环境使用风险仍旧很高。
分布式关系型数据库DRDS则在保持关系模型的特性和数据库高扩展性发做了很好的平衡,实现数据库的高扩展性的同时,也最大化的保持了关系型数据ACID特性和事务一致性。
DRDS产品在阿里巴巴集团内部的对应产品是TDDL,2008年开始大规模接入内部核心系统生产环境,是阿里巴巴近千核心应用首选组件。
DRDS在2014年6月开始公测,2014年12月DRDS正式上线时已稳定服务8年以上,是阿里巴巴8年技术沉淀的结晶。
3DRDS突破数据库极限
数据库的第一个极限就是高扩展性。
基于2008年左右分布式数据库领域比较流行的数据拆分理论,淘宝开始自主研发分布式关系型数据库服务来解决数据库扩展的问题,并于2008年上线TDDL/DRDS服务。
DRDS底层采用分布式的架构,通过“分而治之”拆分原理,将单机数据库实例进行多实例拆分,依据拆分纬度将业务的数据拆分到单机数据库实例集群上。
同时保持对应用层使用逻辑上完全透明,应用层仍旧保持单机数据一致的使用方式,但是扩展性却大大提升。
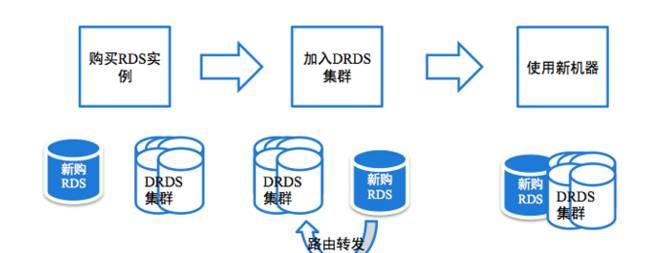
目前DRDS已经可以做到完全平滑的扩容,当数据库的容量或者处理能力不足的时候,只需要简单的“加机器”就能够实现数据库能力的线性扩展,而整个过程可以做到应用透明无感知。
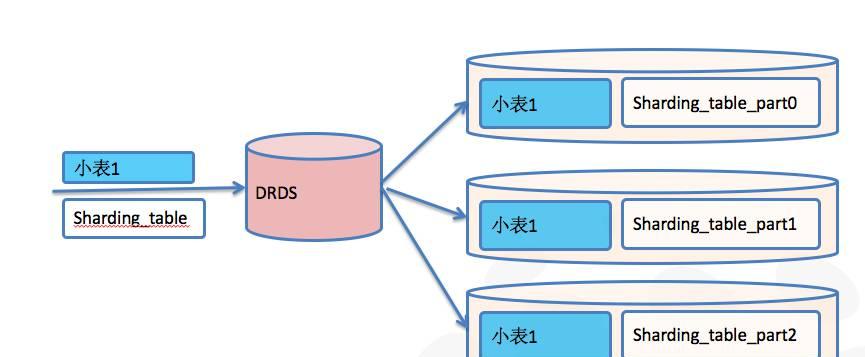
分布式关系型数据库的另外一个极大挑战,在于分布式环境下跨库SQL查询效率。
分布式架构下逻辑单库单表数据会分拆到不同的物理分库分表上,当分库分表和业务源信息小表JOIN的时候,必然需要将分库分表和小表数据先读取然后做合并JOIN,这就造成存在大量的跨物理单库的IO操作,分布式SQL的执行效率会大大降低。
而DRDS的小表复制功能可以通过简单的小表广播配置,将JOIN的驱动小表配置成广播表,将广播表的数据实时广播到分库分表上,这样就将跨库的JOIN变成单机JOIN操作,系统的性能就得到了极大的提升。
分布式关系型数据库的另外一个巨大极限挑战在分布式数据库的数据拆分纬度是单一的,而实际数据使用纬度多样的。
当数据拆分纬度和数据使用纬度不一致的时候,单条SQL会下发到多个物理的分库执行,当分库分表数量达到百甚至千级别的时候,大量的SQL下发和归并操作也会造成巨大的IO性能消耗,造成系统的整体性能直线下降。
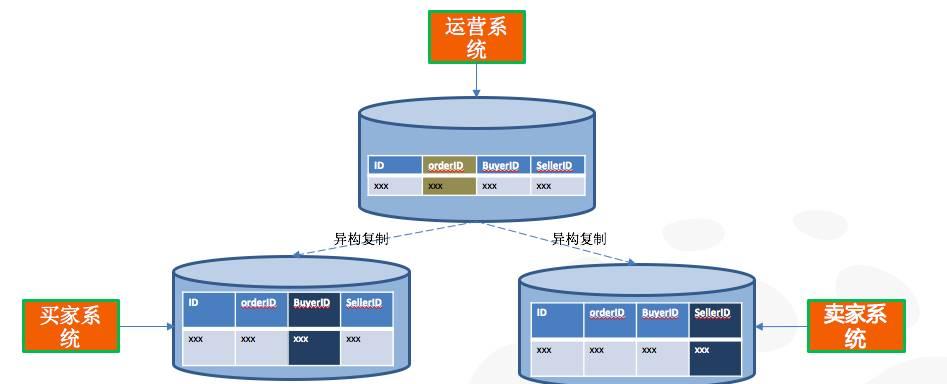
DRDS能够通过异构复制的功能,使用“空间换性能”的方式将同一份数据冗余多份,多份数据按照不同的业务使用场景进行拆分,保持了业务使用纬度和数据拆分纬度的一致性,SQL跨库查询变成了物理单库查询,避免了大量IO操作,系统性能大幅提升。
DRDS提供的另外一个重要核心特性就是“透明读写分离”功能。
读写分离是关系型数据库使用频度非常高的功能,但是传统单机数据库的读写分离和应用的耦合性非常高,应用需要从代码层面分别操作读实例和主实例、读写分离的读写流量分配、读实例的扩容以及特定SQL读写路由也需要修改代码的来实现,这就造成了很大运维成本,应用的代码复杂度增加。
同时,在面对突然暴增的业务流量情况下数据库不能够提供快速的读写分离扩容机制,对业务来说是非常大的不稳定因素。
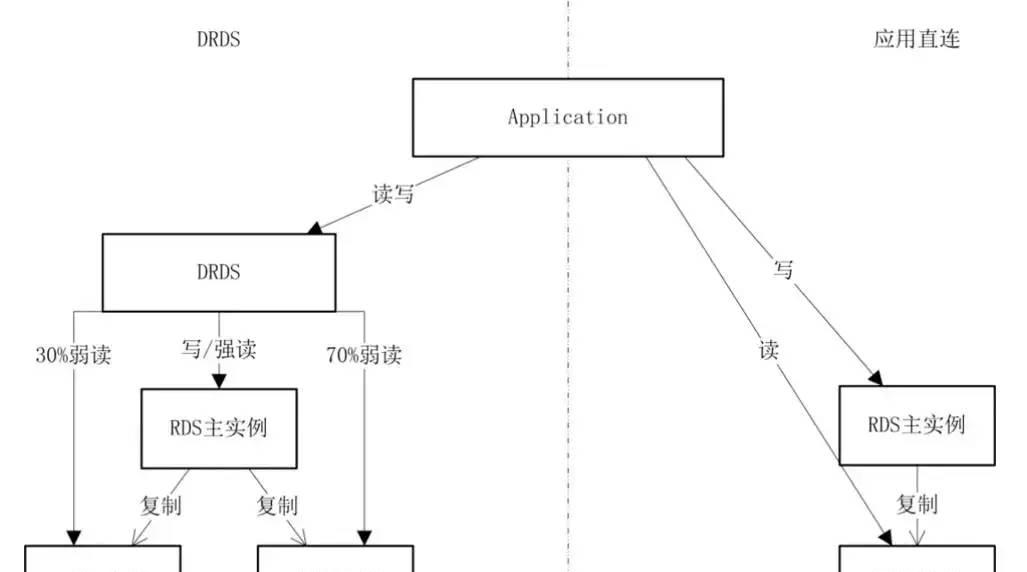
DRDS能够做到对应用完全透明的读写分离,将数据库和应用层完全解耦,应用不需要关心底层的读写分离的路由具体实现,数据库的连接串不需要修改。
只需要在控制台增加只读实例和配置读写流量分配比例,DRDS就可以依据SQL进行读写路由,同时可以实时在控制台变更和查询读写流量的分配比例,对于一些特殊的SQL如果需要强制路由到读实例或者主实例执行,也可以通过DRDS特性的hint语法实现差异化的路由规则,这对于数据库的运维效率是质的提升。
透明的读写分离功能无论对于初创企业还是复杂业务场景的大型企业,都可以大大降低数据库运维成本,降低应用代码复杂度,短期内就可以具备专业的数据库运维能力,系统的稳定性也得到很好的保证。
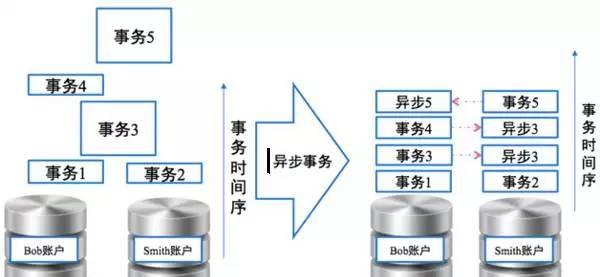
DRDS具有完整的分布式事务套件、完美的支持分布式事务,DRDS可以做到“读提交”级别的分布式事务支持,能够满足90%以上的事务需求场景。
同时,基于阿里云长期对事务的实践得出的经验,大部分的事务场景都不是真正的强一致的事务场景,建议通过异步的事务解耦,将强事务转换为异步的事务序列,可以获得系统扩展性和系统性能的大幅提升。
4DRDS优势
总体来讲,DRDS突破了单机数据关系型数据库强依赖硬件且扩展能力有限的困境,通过分布式集群架构方案真正实现了“无限平滑扩容”。
DRDS具备高扩展性和专业的运维能力的同时保持了简单易用的优势。
DRDS全面兼容MySQL协议和语法,支持大部分MySQL Client。
通过DRDS提供的一键扩容,一键数据迁移,透明的读写分离功能可以帮助企业迅速获得大型互联网企业多年积累的专业数据库运维能力。
5更多精彩
近期,云栖社区组织了一场在线培训,主题是《脸萌Faceu的分布式数据库实践》。
Faceu是DRDS的经典客户。
在本次分享中,脸萌CTO王中飞为大家分享了脸萌团队新产品Faceu在分布式数据库方面的技术实战。
比如为何选择DRDS、使用DRDS中的一些经验。
本文分享嘉宾、阿里云中间件产品经理凤豪也在节目出镜,为大家介绍DRDS背后的技术沉淀。