大家好,今天给大家带来指标实施体系中关于落地实施方案的一点经验,希望可以在日常的数据采集中对大家有所帮助。

GrowingIO 高级技术顾问,毕业于北京大学,Extron 认证工程师。服务过奇瑞汽车、中铁建工、滴滴等头部企业,有丰富的技术部署经验。
1.数据质量是数据分析的基石
假设一个场景:我们想要采集一个广告投放页的数据。
大部分非目标客户都会很急躁的退出广告详情页,而真正看到广告并感兴趣的人员则会主动进入广告详情页。
通过上述例子,我们得出结论:数据采集的时机和技术侧的实现方式会大大影响业务侧的决策。
“九层之台,起于累土。”在形成一套可被洞察的数据之前,数据采集是最基础也是最关键的步骤。只有数据采得准,这个洞察结果才能在你做商业决策时提供帮助。否则将适得其反,再漂亮的数据分析也带不来实际的效果。
但是在埋点方案的实际实施过程中,我们可能会遇到以下困惑:
如何和技术端沟通你的埋点需求?
技术同学是否很快理解并落地?
最终数据生产结果是否符合你的预期?
GrowingIO 在与上百家客户落地埋点方案的经验中,发现“数据采集带来的数据质量问题”也许已经成为了企业的共性问题,而导致这一问题发生的原因主要有以下 4 点:
采集时机口径对不齐。你希望采集数据的那个时机,技术同学并不明确;
版本更新。比如你在新旧版本之间进行比对时,无法发现数据的变化。
数据采集关乎数据质量,它需要产品及业务侧同事做出让技术同学“看得懂、埋的对、实施快”的技术落地方案。
2.GrowingIO 为数据高效采集保驾护航
针对这些棘手问题,GrowingIO 的无埋点技术可以快捷定义页面、按钮、文本框等常见用户行为操作,从而减少在某些重复性高的用户共性行为的埋点代码操作量,为数据快速可视化提供便利。
1.无埋点的定义
什么是无埋点?我们先来看看你是否遇到过以下这些场景:
想衡量交互细节以推测用户行为之间的关联,却苦恼于繁琐的工序;
想查看用户在访问时的一切行为轨迹,探索用户使用产品场景;
想要快速地对比新旧版本,衡量发版效果;
想要分析的事件,没有事先埋点;
新功能上线时,发现有一个重要的元素没有埋点。
针对以上问题,无埋点都可以很好的解决。其实无埋点就是人物、时间、地点、内容、方式的数据采集方式,通过 GrowingIO 的圈选(可视化定义工具)功能,我们可以所见即所得地定义指标。
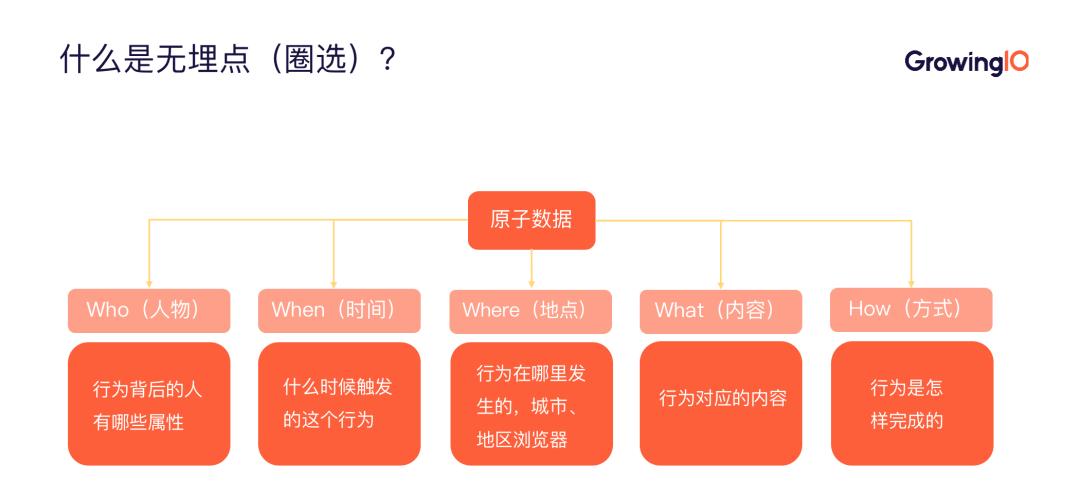
无埋点(圈选)的核心思想基于以下 5 个元数据:
人物:人的属性,包括 ID、性别、所在区域等;
时间:触发行为的时间;
地点:行为发生的城市、地区浏览器等;
内容:行为的对象,如按钮等;
无埋点能够定义常见事件类型,尽可能地减少代码的使用,减少开发工作量。通过 GrowingIO 的圈选功能,我们能快速采集数据、定义指标、查看实时数据。
2.埋点和无埋点如何选择?
新的无埋点虽然简单便捷,但也有它自身的局限性。同时,我们离不开业务数据维度,所以传统埋点也不能放弃。
埋点和无埋点各有优势,面对不同的场景,我们需要明确目的、结合具体情况综合判断,选择数据采集的最优方式。
(1)埋点
优势
数据定义清晰,稳定性高,用户一旦触发事件,数据就能上报;
可以多次添加业务属性,以支持维度拆解和下钻分析。
劣势
需要提前规划,和开发团队沟通业务需求,跨团队协作确定埋点方案;
历史数据无法回溯,在下一个版本中才能看到。
适用于「监控与分析式」数据场景:
核心 KPI 数据
需要长期监控和存储
业务属性丰富
(2)无埋点
优势
自主性高,可实时查看数据,便于灵活采集;
无需等到发版便可回溯过去 7 天数据。
劣势
受制于产品开发框架和开发规范,任何一个路径发生改变都会产生影响;
维度预定义,无法拆分事件级维度,且无法采集滑动等行为。
适用于「探索式」数据场景:
交互属性强
突发问题快速及时分析
作为补充数据相互印证
综合以上,我们整理出了以下表格,方便大家更好的理解和选择:

总之,埋点技术灵活、稳定、局限性低、精度高,适合跟踪关键节点,隐藏程序逻辑搭配业务维度观察的数据。
无埋点技术确定快,有历史数据,有预定义维度加持,适合快速查看某些趋势型或流程型数据。
如果存在该预定义指标(即无埋点),且预定义维度也满足需求,那么,我们就要针对该无埋点的指标和维度进行观察,可放心选择无埋点。如果不存在或预定义维度无法满足观察该指标的角度,则需要通过埋点指标进行上报。
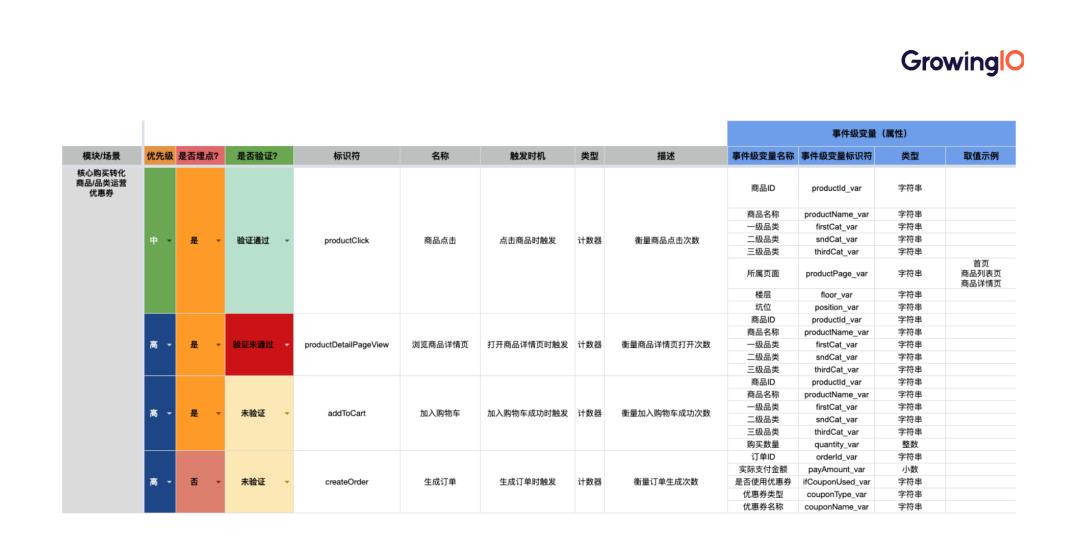
3.完整埋点方案设计的四要素
在规划完指标体系后,推进实施是价值落地过程中最重要的一环。
很多客户即使对要监控的数据体系相当明确,也仍然会在实施时遇到瓶颈。这很大程度上归结于团队协作问题,例如数据埋点工程量大、沟通成本高、业务方与开发方无法统一目标等。
这最终会导致我们空有体系,无数可看。
如果将一整套的数据采集方案直接给到研发侧,业务场景描述和逻辑理解的差异会造成大量的沟通成本,最终导致低迷的实施效率。
所以,我们需要将条理化的指标体系梳理成实施需求。而解决该问题的关键点在于以下 4 个步骤:
1.确认事件与变量
变量:事件的维度或属性,比如用户性别、商品的种类;

如果从不同的角度去定位一个问题,它的事件和变量也会发生改变。我们要基于数据需求,找到事件与变量搭配的最优解。
2.明确事件的触发时机
所有数据使用者需要明确这一时机。

时机的选择没有对错,需要根据具体的业务需求来制定。同时,不同的触发时机会带来不同的数据口径。
3.规范命名
举个例子:某客户给双十一活动命名时采用拼音与英文结合的方式,这会使得程序员产生混淆,错误埋点。而规范的命名有利于程序员理解业务需求,高效落地埋点方案。
使用驼峰法,即首字母小写,随后每一个关键单词的首字母大写:如 addToCart。
确保事件命名规范一致。

4.明确实施优先级
业务部门必须基于业务指标,明确实施埋点的优先级。因为对于大量事件,开发部门不可能一次性完成所有埋点。以电商为例,购买流程的关键事件应当优先实施,与此冲突的都需往后排列;
考虑技术实现成本,比如有的埋点需要跨越多个接口,应该优先落实能够最快落地的,以确保技术准确性;
如果技术实现成本相同,就优先实施业务数据价值更高的。

通过明确优先级,我们可以专注于产品中需要跟踪的真正重要事件,避免技术埋点冲突,实现价值的持续交付。
基于上述四要素来完成埋点方案设计,不仅可以提升需求方与开发团队的协作效率,更能为后期的数据提供质量保障。
以下表格是我们整理出的模板,该表格完整承接埋点方案设计的四要素,可直接交给技术方进行埋点。