https://juejin.im/post/6868073137263607821

Python 操作 Excel常用工具
数据处理是 Python 的一大应用场景,而 Excel 又是当前最流行的数据处理软件。因此用 Python 进行数据处理时,很容易会和 Excel 打起交道。得益于前人的辛勤劳作,Python 处理 Excel 已有很多现成的轮子,比如xlrd & xlwt & xlutils、XlsxWriter、OpenPyXL,而在 Windows 平台上可以直接调用 Microsoft Excel 的开放接口,这些都是比较常用的工具,还有其他一些优秀的工具这里就不一一介绍,接下来我们通过一个表格展示各工具之间的特点:
类型xlrd&xlwt&xlutilsXlsxWriterOpenPyXLExcel开放接口读取支持不支持支持支持写入支持支持支持支持修改支持不支持支持支持xls支持不支持不支持支持xlsx高版本支持支持支持大文件不支持支持支持不支持效率快快快超慢功能较弱强大一般超强大
以上可以根据需求不同,选择合适的工具,现在为大家主要介绍下最常用的 xlrd & xlwt & xlutils 系列工具的使用。
xlrd & xlwt & xlutils 介绍
xlrd&xlwt&xlutils 是由以下三个库组成:
xlrd:用于读取 Excel 文件;xlwt:用于写入 Excel 文件;xlutils:用于操作 Excel 文件的实用工具,比如复制、分割、筛选等;安装库
安装比较简单,直接用 pip 工具安装三个库即可,安装命令如下:
$pipinstallxlrdxlwtxlutils



写入 Excel
接下来我们就从写入 Excel 开始,话不多说直接看代码如下:
#导入xlwt库importxlwt#创建xls文件对象wb=xlwt.Workbook()#新增两个表单页sh1=wb.add_sheet(‘成绩’)sh2=wb.add_sheet(‘汇总’)#然后按照位置来添加数据,第一个参数是行,第二个参数是列#写入第一个sheetsh1.write(0,0,’姓名’)sh1.write(0,1,’专业’)sh1.write(0,2,’科目’)sh1.write(0,3,’成绩’)sh1.write(1,0,’张三’)sh1.write(1,1,’信息与通信工程’)sh1.write(1,2,’数值分析’)sh1.write(1,3,88)sh1.write(2,0,’李四’)sh1.write(2,1,’物联网工程’)sh1.write(2,2,’数字信号处理分析’)sh1.write(2,3,95)sh1.write(3,0,’王华’)sh1.write(3,1,’电子与通信工程’)sh1.write(3,2,’模糊数学’)sh1.write(3,3,90)#写入第二个sheetsh2.write(0,0,’总分’)sh2.write(1,0,273)#最后保存文件即可wb.save(‘test.xls’)
运行代码,结果会看到生成名为 test.xls 的 Excel 文件,打开文件查看如下图所示:
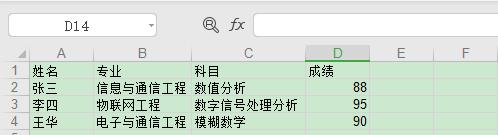
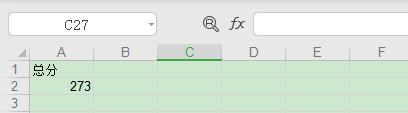
以上就是写入 Excel 的代码,是不是很简单,下面我们再来看下读取 Excel 该如何操作。
读取 Excel
读取 Excel 其实也不难,请看如下代码:
#导入xlrd库importxlrd#打开刚才我们写入的test_w.xls文件wb=xlrd.open_workbook(“test_w.xls”)#获取并打印sheet数量print(“sheet数量:”,wb.nsheets)#获取并打印sheet名称print(“sheet名称:”,wb.sheet_names())#根据sheet索引获取内容sh1=wb.sheet_by_index(0)#或者#也可根据sheet名称获取内容#sh=wb.sheet_by_name(‘成绩’)#获取并打印该sheet行数和列数print(u”sheet%s共%d行%d列”%(sh1.name,sh1.nrows,sh1.ncols))#获取并打印某个单元格的值print(“第一行第二列的值为:”,sh1.cell_value(0,1))#获取整行或整列的值rows=sh1.row_values(0)#获取第一行内容cols=sh1.col_values(1)#获取第二列内容#打印获取的行列值print(“第一行的值为:”,rows)print(“第二列的值为:”,cols)#获取单元格内容的数据类型print(“第二行第一列的值类型为:”,sh1.cell(1,0).ctype)#遍历所有表单内容forshinwb.sheets():forrinrange(sh.nrows):#输出指定行print(sh.row(r))
输出如下结果:

细心的朋友可能注意到,这里我们可以获取到单元格的类型,上面我们读取类型时获取的是数字1,那1表示什么类型,又都有什么类型呢?别急下面我们通过一个表格展示下:
数值类型说明0empty空1string字符串2number数字3date日期4boolean布尔值5error错误
通过上面表格,我们可以知道刚获取单元格类型返回的数字1对应的就是字符串类型。
修改 excel
上面说了写入和读取 Excel 内容,接下来我们就说下更新修改 Excel 该如何操作,修改时就需要用到 xlutils 中的方法了。直接上代码,来看下最简单的修改操作:
#导入相应模块importxlrdfromxlutils.copyimportcopy#打开excel文件readbook=xlrd.open_workbook(“test_w.xls”)#复制一份wb=copy(readbook)#选取第一个表单sh1=wb.get_sheet(0)#在第五行新增写入数据sh1.write(4,0,’王欢’)sh1.write(4,1,’通信工程’)sh1.write(4,2,’机器学习’)sh1.write(4,3,89)#选取第二个表单sh1=wb.get_sheet(1)#替换总成绩数据sh1.write(1,0,362)#保存wb.save(‘test.xls’)
从上面代码可以看出,这里的修改 Excel 是通过 xlutils 库的 copy 方法将原来的 Excel 整个复制一份,然后再做修改操作,最后再保存。看下修改结果如下:
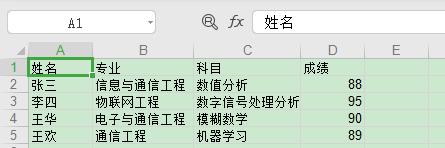
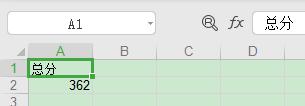
格式转换操作
在平时我们使用 Excel 时会对数据进行一下格式化,或者样式设置,在这里把上面介绍写入的代码简单修改下,使输出的格式稍微改变一下,代码如下:
#导入xlwt库importxlwt#设置写出格式字体红色加粗styleBR=xlwt.easyxf(‘font:nameTimesNewRoman,color-indexred,boldon’)#设置数字型格式为小数点后保留两位styleNum=xlwt.easyxf(num_format_str=’#,##0.00′)#设置日期型格式显示为YYYY-MM-DDstyleDate=xlwt.easyxf(num_format_str=’YYYY-MM-DD’)#创建xls文件对象wb=xlwt.Workbook()#新增两个表单页sh1=wb.add_sheet(‘成绩’)sh2=wb.add_sheet(‘汇总’)#然后按照位置来添加数据,第一个参数是行,第二个参数是列sh1.write(0,0,’姓名’,styleBR)#设置表头字体为红色加粗sh1.write(0,1,’日期’,styleBR)#设置表头字体为红色加粗sh1.write(0,2,’成绩’,styleBR)#设置表头字体为红色加粗#插入数据sh1.write(1,0,’张三’,)sh1.write(1,1,’2020-07-01′,styleDate)sh1.write(1,2,90,styleNum)sh1.write(2,0,’李四’)sh1.write(2,1,’2020-08-02′)sh1.write(2,2,95,styleNum)#设置单元格内容居中的格式alignment=xlwt.Alignment()alignment.horz=xlwt.Alignment.HORZ_CENTERstyle=xlwt.XFStyle()style.alignment=alignment#合并A4,B4单元格,并将内容设置为居中sh1.write_merge(3,3,0,1,’总分’,style)#通过公式,计算C2 C3单元格的和sh1.write(3,2,xlwt.Formula(“C2 C3”))#对sheet2写入数据sh2.write(0,0,’总分’,styleBR)sh2.write(1,0,185)#最后保存文件即可wb.save(‘test.xls’)
输出结果:
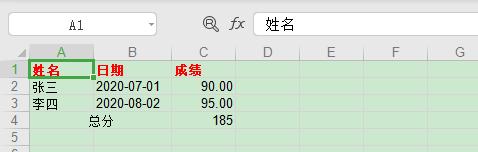
可以看出,使用代码我们可以对字体,颜色、对齐、合并等平时 Excel 的操作进行设置,也可以格式化日期和数字类型的数据。当然了这里只是介绍了部分功能,不过这已经足够我们日常使用了,想了解更多功能操作可以参考官网。
python-excel官网:www.python-excel.org/
Python 操作 Word安装 python-docx
处理 Word 需要用到python-docx库,目前版本为0.8.10,执行如下安装命令:
$pipinstallpython-docx#################运行结果################C:\Users\Y>pipinstallpython-docxLookinginindexes:https://pypi.doubanio.com/simpleCollectingpython-docxDownloadinghttps://pypi.doubanio.com/packages/e4/83/c66a1934ed5ed8ab1dbb9931f1779079f8bca0f6bbc5793c06c4b5e7d671/python-docx-0.8.10.tar.gz(5.5MB)|████████████████████████████████|5.5MB3.2MB/sRequirementalreadysatisfied:lxml>=2.3.2inc:\users\y\appdata\local\programs\python\python37\lib\site-packages(frompython-docx)(4.5.0)Buildingwheelsforcollectedpackages:python-docxBuildingwheelforpython-docx(setup.py)…doneCreatedwheelforpython-docx:filename=python_docx-0.8.10-cp37-none-any.whlsize=184496sha256=7ac76d3eec848a255b4f197d07e7b78ab33598c814d536d9b3c90b5a3e2a57fbStoredindirectory:C:\Users\Y\AppData\Local\pip\Cache\wheels\05\7d\71\bb534b75918095724d0342119154c3d0fc035cedfe2f6c9a6cSuccessfullybuiltpython-docxInstallingcollectedpackages:python-docxSuccessfullyinstalledpython-docx-0.8.10复制代码
OK,如果提示以上信息则安装成功。
写入 Word
平时我们在操作 Word 写文档的时候,一般分为几部分:标题、章节、段落、图片、表格、引用以及项目符号编号等。下面我们就按这几部分如何用 Python 操作来一一介绍。
标题
文档标题创建比较简单,通过Document()创建出一个空白文档,只要调用add_heading方法就能创建标题。
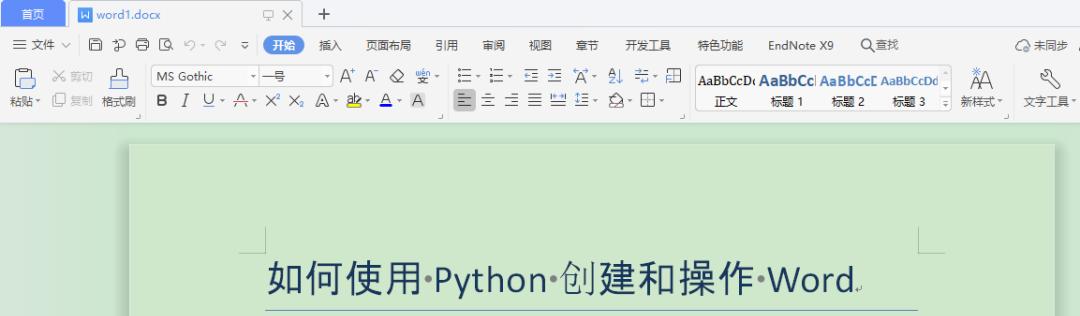
#导入库fromdocximportDocumentfromdocx.sharedimportPtfromdocx.sharedimportInchesfromdocx.oxml.nsimportqn#新建空白文档doc1=Document()#新增文档标题doc1.add_heading(‘如何使用Python创建和操作Word’,0)#保存文件doc1.save(‘word1.docx’)
这样就完成了创建文档和文章标题的操作,下面运行程序,会生成名为 word1.docx 的文档,打开文章显示如下图所示:
章节与段落
有了文章标题,下面我们来看章节和段落是怎么操作的,在上面代码后面增加章节和段落操作的代码如下:
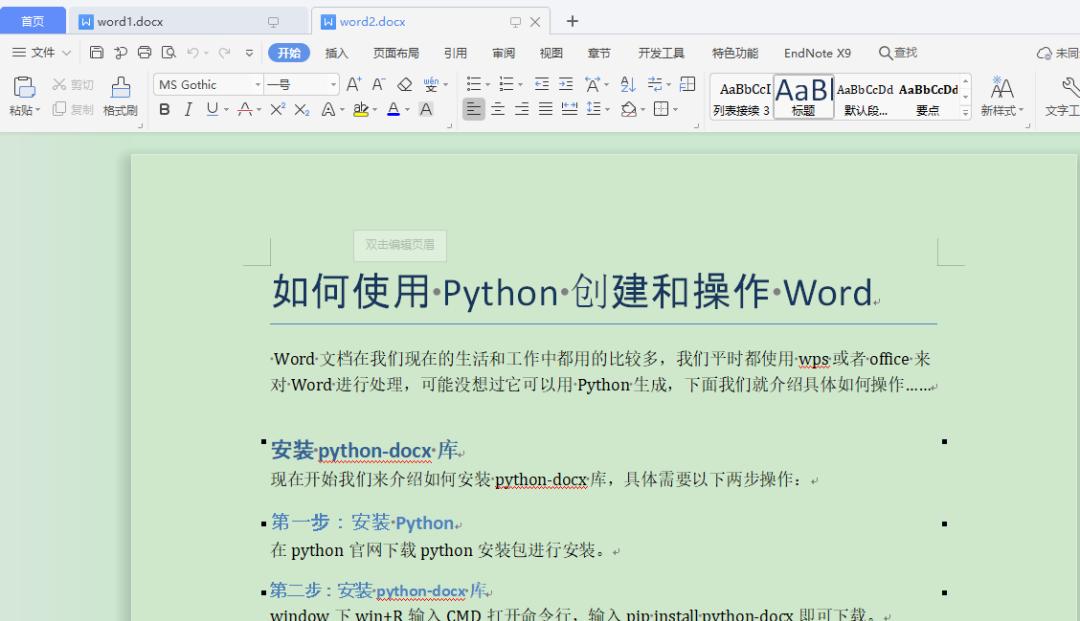
#导入库fromdocximportDocumentfromdocx.sharedimportPtfromdocx.sharedimportInchesfromdocx.oxml.nsimportqn#新建空白文档doc1=Document()#新增文档标题doc1.add_heading(‘如何使用Python创建和操作Word’,0)#创建段落描述doc1.add_paragraph(‘Word文档在我们现在的生活和工作中都用的比较多,我们平时都使用wps或者office来对Word进行处理,可能没想过它可以用Python生成,下面我们就介绍具体如何操作……’)#创建一级标题doc1.add_heading(‘安装python-docx库’,1)#创建段落描述doc1.add_paragraph(‘现在开始我们来介绍如何安装 python-docx 库,具体需要以下两步操作:’)#创建二级标题doc1.add_heading(‘第一步:安装 Python’,2)#创建段落描述doc1.add_paragraph(‘在python官网下载python安装包进行安装。’)#创建三级标题doc1.add_heading(‘第二步:安装 python-docx 库’,3)#创建段落描述doc1.add_paragraph(‘window下win R输入CMD打开命令行,输入pip install python-docx即可下载。’)#保存文件doc1.save(‘word2.docx’)
上面我们说了 add_heading 方法用来增加文章标题,不过通过上面代码我们能知道,这个方法的第二个参数为数字,其实这个就是用来标示几级标题的,在我们平时就用来标示章节。add_paragraph 方法则是用来在文章中增加段落的, 运行程序看下效果:
字体和引用
前面我们通过 add_paragraph 方法增加了三个段落,现在我们就看下如何对段落中字体如何操作,以及引用段落的操作。继续修改以上代码,增加对文章字体字号、加粗、倾斜等操作,具体代码如下:
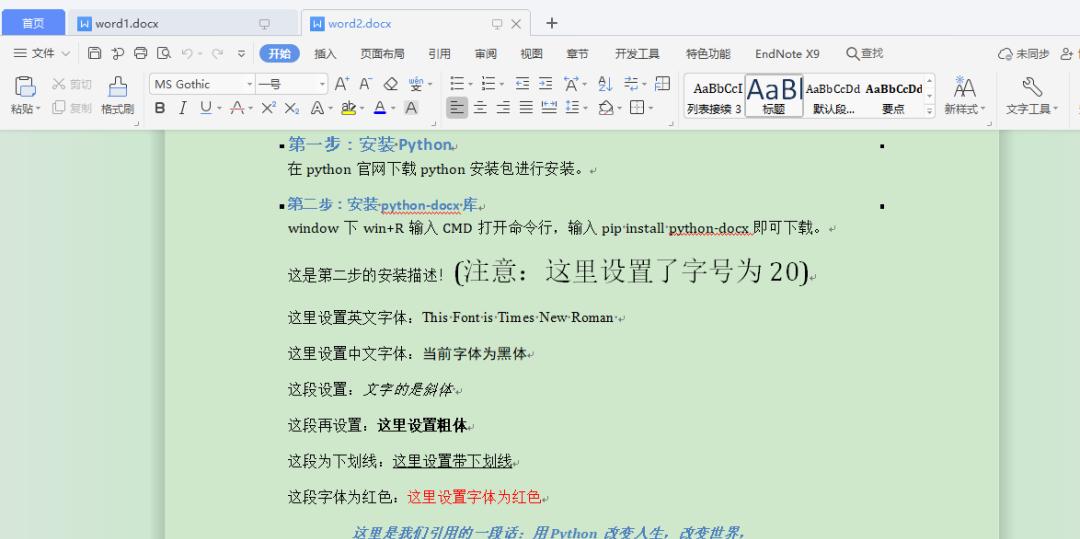
#导入库fromdocximportDocumentfromdocx.sharedimportPtfromdocx.sharedimportInchesfromdocx.oxml.nsimportqnfromdocx.sharedimportRGBColor#新建空白文档doc1=Document()#新增文档标题doc1.add_heading(‘如何使用Python创建和操作Word’,0)#创建段落描述doc1.add_paragraph(‘Word文档在我们现在的生活和工作中都用的比较多,我们平时都使用wps或者office来对Word进行处理,可能没想过它可以用Python生成,下面我们就介绍具体如何操作……’)#创建一级标题doc1.add_heading(‘安装python-docx库’,1)#创建段落描述doc1.add_paragraph(‘现在开始我们来介绍如何安装 python-docx 库,具体需要以下两步操作:’)#创建二级标题doc1.add_heading(‘第一步:安装 Python’,2)#创建段落描述doc1.add_paragraph(‘在python官网下载python安装包进行安装。’)#创建三级标题doc1.add_heading(‘第二步:安装 python-docx 库’,3)#创建段落描述doc1.add_paragraph(‘window下win R输入CMD打开命令行,输入pip install python-docx即可下载。’)#创建段落,添加文档内容paragraph=doc1.add_paragraph(‘这是第二步的安装描述!’)#段落中增加文字,并设置字体字号run=paragraph.add_run(‘(注意:这里设置了字号为20)’)run.font.size=Pt(20)#设置英文字体run=doc1.add_paragraph(‘这里设置英文字体:’).add_run(‘ThisFontisTimesNewRoman’)run.font.name=’TimesNewRoman’#设置中文字体run=doc1.add_paragraph(‘这里设置中文字体:’).add_run(‘当前字体为黑体’)run.font.name=’黑体’r=run._elementr.rPr.rFonts.set(qn(‘w:eastAsia’),’黑体’)#设置斜体run=doc1.add_paragraph(‘这段设置:’).add_run(‘文字的是斜体’)run.italic=True#设置粗体run=doc1.add_paragraph(‘这段再设置:’).add_run(‘这里设置粗体’).bold=True#设置字体带下划线run=doc1.add_paragraph(‘这段为下划线:’).add_run(‘这里设置带下划线’).underline=True#设置字体颜色run=doc1.add_paragraph(‘这段字体为红色:’).add_run(‘这里设置字体为红色’)run.font.color.rgb=RGBColor(0xFF,0x00,0x00)#增加引用doc1.add_paragraph(‘这里是我们引用的一段话:用Python改变人生,改变世界,FIGHTING。’,style=’IntenseQuote’)#保存文件doc1.save(‘word2.docx’)
上面代码主要是针对段落字体的各种设置,每段代码都标有注释应该比较容易理解, 运行程序看下效果:
项目列表
我们平时在使用 Word 时,为了能展示更清晰,会用到项目符号和编号,将内容通过列表的方式展示出来,下面我们新建一个文件 word1.py 并编写如下代码:
#导入库fromdocximportDocumentfromdocx.sharedimportPtfromdocx.sharedimportInchesfromdocx.oxml.nsimportqn#新建文档doc2=Document()doc2.add_paragraph(‘哪个不是动物:’)#增加无序列表doc2.add_paragraph(‘苹果’,style=’ListBullet’)doc2.add_paragraph(‘喜洋洋’,style=’ListBullet’)doc2.add_paragraph(‘懒洋洋’,style=’ListBullet’)doc2.add_paragraph(‘沸洋洋’,style=’ListBullet’)doc2.add_paragraph(‘灰太狼’,style=’ListBullet’)doc2.add_paragraph(‘2020年度计划:’)#增加有序列表doc2.add_paragraph(‘CSDN达到博客专家’,style=’ListNumber’)doc2.add_paragraph(‘每周健身三天’,style=’ListNumber’)doc2.add_paragraph(‘每天学习一个新知识点’,style=’ListNumber’)doc2.add_paragraph(‘学习50本书’,style=’ListNumber’)doc2.add_paragraph(‘减少加班时间’,style=’ListNumber’)#保存文件doc2.save(‘word1.docx’)

图片和表格
#导入库fromdocximportDocumentfromdocx.sharedimportPtfromdocx.sharedimportInchesfromdocx.oxml.nsimportqn#新建文档doc2=Document()doc2.add_paragraph(‘哪个不是动物:’)#增加无序列表doc2.add_paragraph(‘苹果’,style=’ListBullet’)doc2.add_paragraph(‘喜洋洋’,style=’ListBullet’)doc2.add_paragraph(‘懒洋洋’,style=’ListBullet’)doc2.add_paragraph(‘沸洋洋’,style=’ListBullet’)doc2.add_paragraph(‘灰太狼’,style=’ListBullet’)doc2.add_paragraph(‘2020年度计划:’)#增加有序列表doc2.add_paragraph(‘CSDN达到博客专家’,style=’ListNumber’)doc2.add_paragraph(‘每周健身三天’,style=’ListNumber’)doc2.add_paragraph(‘每天学习一个新知识点’,style=’ListNumber’)doc2.add_paragraph(‘学习50本书’,style=’ListNumber’)doc2.add_paragraph(‘减少加班时间’,style=’ListNumber’)doc2.add_heading(‘图片’,2)#增加图像doc2.add_picture(‘C:/Users/Y/Pictures/python-logo.png’,width=Inches(5.5))doc2.add_heading(‘表格’,2)#增加表格,这是表格头table=doc2.add_table(rows=1,cols=4)hdr_cells=table.rows[0].cellshdr_cells[0].text=’编号’hdr_cells[1].text=’姓名’hdr_cells[2].text=’职业’#这是表格数据records=((1,’张三’,’电工’),(2,’张五’,’老板’),(3,’马六’,’IT’),(4,’李四’,’工程师’))#遍历数据并展示forid,name,workinrecords:row_cells=table.add_row().cellsrow_cells[0].text=str(id)row_cells[1].text=namerow_cells[2].text=work#手动增加分页doc2.add_page_break()#保存文件doc2.save(‘word1.docx’)
读取 Word 文件
上面写了很多用 Python 创建空白 Word 文件格式化字体并保存到文件中,接下来我们再简单介绍下如何读取已有的 Word 文件,请看如下代码:
#引入库fromdocximportDocument#打开文档1doc1=Document(‘word1.docx’)#读取每段内容pl=[paragraph.textforparagraphindoc1.paragraphs]print(‘######输出word1文章的内容######’)#输出读取到的内容foriinpl:print(i)#打开文档2doc2=Document(‘word2.docx’)print(‘\n######输出word2文章内容######’)pl2=[paragraph.textforparagraphindoc2.paragraphs]#输出读取到的内容forjinpl2:print(j)#读取表格材料,并输出结果tables=[tablefortableindoc2.tables]fortableintables:forrowintable.rows:forcellinrow.cells:print(cell.text,end=”)print()print(‘\n’)
以上代码是将之前我们输出的两个文档内容都读取出来,当然这里只是打印到控制台,并没有做其他处理。现在我们执行看下结果:

Python 操作 CSV简介CSV
CSV全称Comma-Separated Values,中文叫逗号分隔值或字符分隔值,它以纯文本形式存储表格数据(数字和文本),其本质就是一个字符序列,可以由任意数目的记录组成,记录之间以某种换行符分隔,每条记录由字段组成,通常所有记录具有完全相同的字段序列,字段间常用逗号或制表符进行分隔。CSV 文件格式简单、通用,在现实中有着广泛的应用,其中使用最多的是在程序之间转移表格数据。
CSV 与 Excel
因为 CSV 文件与 Excel 文件默认都是用 Excel 工具打开,那他们有什么区别呢?我们通过下表简单了解一下。
Python 通过csv 模块来实现 CSV 格式文件中数据的读写,该模块提供了兼容 Excel 方式输出、读取数据文件的功能,这样我们无需知道 Excel 所采用 CSV 格式的细节,同样的它还可以定义其他应用程序可用的或特定需求的 CSV 格式。
csv 模块中使用reader 类和writer 类读写序列化的数据,使用DictReader 类和DictWriter 类以字典的形式读写数据,下面来详细看一下相应功能。首先来看一下 csv 模块常量信息,如下所示:
属性说明QUOTE_ALL指示 writer 对象给所有字段加上引号QUOTE_MINIMAL指示 writer 对象仅为包含特殊字符(如:定界符、引号字符、行结束符等)的字段加上引号QUOTE_NONNUMERIC指示 writer 对象为所有非数字字段加上引号QUOTE_NONE指示 writer 对象不使用引号引出字段writer(csvfile, dialect=’excel’, **fmtparams)
返回一个writer 对象,该对象负责将用户的数据在给定的文件类对象上转换为带分隔符的字符串。
csvfile可以是具有 write() 方法的任何对象,如果 csvfile 是文件对象,则使用 newline=’’ 打开;可选参数dialect 是用于不同的 CSV 变种的特定参数组;可选关键字参数fmtparams可以覆写当前变种格式中的单个格式设置。
看下示例:
importcsvwithopen(‘test.csv’,’w’,newline=”)ascsvfile:writer=csv.writer(csvfile)writer.writerow([‘id’,’name’,’age’])#写入多行data=[(‘1001′,’张三’,’21’),(‘1002′,’李四’,’31’)]writer.writerows(data)
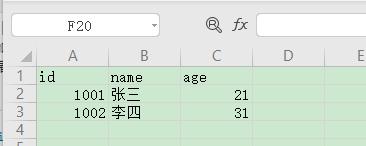
reader(csvfile, dialect=’excel’, **fmtparams)
返回一个reader 对象,该对象将逐行遍历 csvfile,csvfile 可以是文件对象和列表对象,如果是文件对象要使用 newline=’’ 打开。看下示例:
importcsvwithopen(‘test.csv’,newline=”)ascsvfile:reader=csv.reader(csvfile,delimiter=”)forrowinreader:print(‘,’.join(row))

Sniffer 类
用于推断 CSV 文件的格式,该类提供了如下两个方法:
sniff(sample, delimiters=None)
分析给定的 sample,如果给出可选的 delimiters 参数,则该参数会被解释为字符串,该字符串包含了可能的有效定界符。
has_header(sample)
分析示例文本(假定为 CSV 格式),如果第一行很可能是一系列列标题,则返回 True。
该类及方法使用较少,了解即可,下面通过一个示例简单了解一下。
importcsvwithopen(‘test.csv’,newline=”)ascsvfile:dialect=csv.Sniffer().sniff(csvfile.read(1024))csvfile.seek(0)reader=csv.reader(csvfile,dialect)forrowinreader:print(row)Reader 对象
Reader 对象指 DictReader 实例和 reader() 函数返回的对象,下面看一下其公开属性和方法。
next()
返回 reader 的可迭代对象的下一行,返回值可能是列表或字典。
dialect
dialect 描述,只读,供解析器使用。
line_num
源迭代器已经读取了的行数。
fieldnames
字段名称,该属性为 DictReader 对象属性。
Writer 对象
Writer 对象指 DictWriter 实例和 writer() 函数返回的对象,下面看一下其公开属性和方法。
writerow(row)
将参数 row 写入 writer 的文件对象。
writerows(rows)
将 rows_(即能迭代出多个上述_ row 对象的迭代器)中的所有元素写入 writer 的文件对象。
writeheader()
在 writer 的文件对象中,写入一行字段名称,该方法为 DictWriter 对象方法。
dialect
dialect 描述,只读,供 writer 使用。
写读追加状态’r’:读’w’:写’a’:追加’r ‘==r w(可读可写,文件若不存在就报错(IOError))’w ‘==w r(可读可写,文件若不存在就创建)’a ‘==a r(可追加可写,文件若不存在就创建)对应的,如果是二进制文件,就都加一个b就好啦:’rb”wb”ab”rb ”wb ”ab
(完)