00
引言
尤其是近年,移动互联、大数据等技术突飞发展,倒逼传统行业向智能化、移动化方向转型。随着运营效率、各行业的数字化、智能化、自动化的铺开,以OCR识别、数据挖掘为代表的人工智能技术逐渐深入到日常生活的方方面面。
最常见的场景之一,我们在进出高铁站时,机器对我们进行车票信息比对的过程,其实就使用到OCR技术,只是对普通老百姓而言,不知道具体的专业名词而已。

01
什么是OCR技术?

02
OCR常用领域
OCR应用领域很广泛,在很多场合都可取代键盘完成高效的文本录入工作。整体来看,OCR技术的应用推广,OCR技术在国内的起步与应用普及度均落后于国外。国外的OCR技术应用相对成熟,比如:Motorola、HP和 Microsoft等全球性大公司陆续展开这方面研究,在产品中绑定OCR技术。最司空见惯的,微软早期推出的办公套件-Microsoft Office XP中,不仅加强了原有对手写输入的支持,还新增光学字符识别(OCR)的工具组件。大约2008年,Google也宣布将开始在网络蜘蛛程序中使用OCR技术,这样就可以识别许多非格式化文本与图像,并将其索引到结构化与非机构化的数据库。现今,OCR技术在我国的应用也极为广泛,大致可概括为:有汉字的地方就有OCR技术的存在。在信息技术及计算机技术日渐普及的今天,如何将文字方便、快捷地输入到计算机,并能按照人们的意愿,进行更便捷的再创造,成了OCR技术要解决的现实问题。

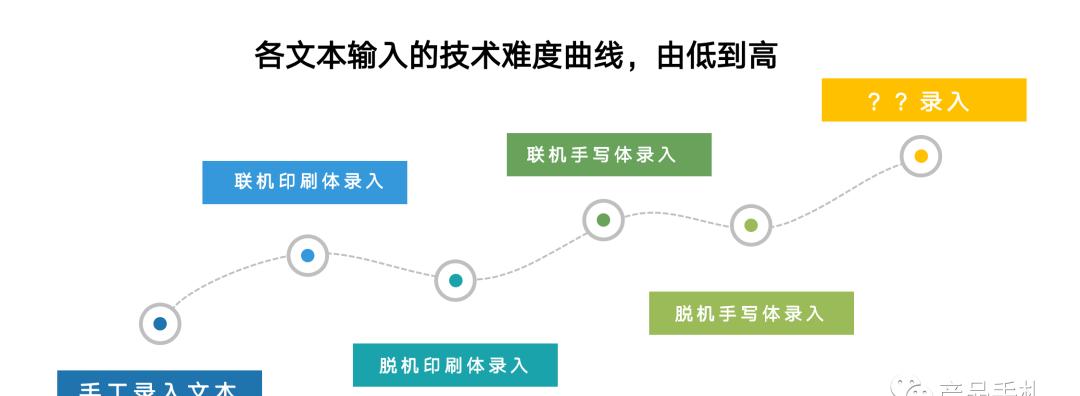
在全世界范围看,文本的输入主要分为三类:人工键盘输入、机器自动识别输入。其中人工键入速度慢且劳动强度大;自动输入又分为文本识别输入及语音识别输入。从识别技术的难度讲,手写体识别的难度高于印刷体,而手写体识别中,离线手写体的难度又远超联机手写体识别。
到目前为止,除了离线手写体数字、字幕、常见汉字等基础的识别已有实际应用外,其他的文本离线手写体识别还处在实验室阶段。简单来说,从影像到结果输出,须经过影像输入、影像前处理、文字特征抽取、比对识别、最后经人工校正将认错的文字更正,将结果输出等环节的过程。至于语音形式的文本输入,我们后续篇幅再专门讲解。各类文本,输入技术难度等级如下图:
随着我国信息化建设全面普及,OCR技术的应用前景将更加地广阔。就目前行业需求看,金融、保险、税务、工商、电子商务等行业对信息识别的需求,已经越来越广泛,促进了识别技术的大规模应用。个人消费电子产品也进一步推动了手写体识别技术的发展,OCR识别技术在个人消费电子领域的应用属于必然趋势。5G网络时代的高速发展,促使个人资料与信息电子化、商务办公等需求,将逐步助推OCR技术以在线识别为主线。所以,后5G时代,OCR技术在手写体、印刷体方面的应用需求,基本可定调为在线识别为主。OCR技术现有应用领域如下:1. 用OCR进行印刷体文稿的识别录入,这是很多办公部门经常使用方法一。国内已有很多这样的产品,这类产品的缺点是对于有表格、图形或图的文稿需要手工进行干预,而且这类产品抗干扰能力较差。2. 可对图形、图像和文本等混排的复杂版面进行自动切分的印刷体识别系统是现在研究的重点之一,由于其完善的功能使之在出版业具有广阔的应前景。3. 邮件自动分拣系统,邮件自动分拣系统是邮政系统提高信函分拣速度有效手段,国内外已普遍使用,其核心技术就是手写体数字的识别。4. 手写体表格数据自动录入系统,可广泛应用于政府、税务、保险、商、医疗、金融、厂矿等各行业的申报表、调查表等表格数据的输入和处理。
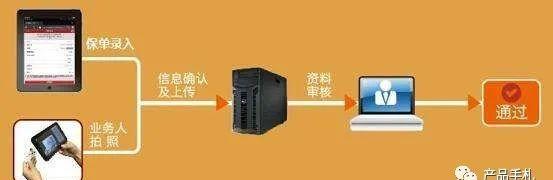
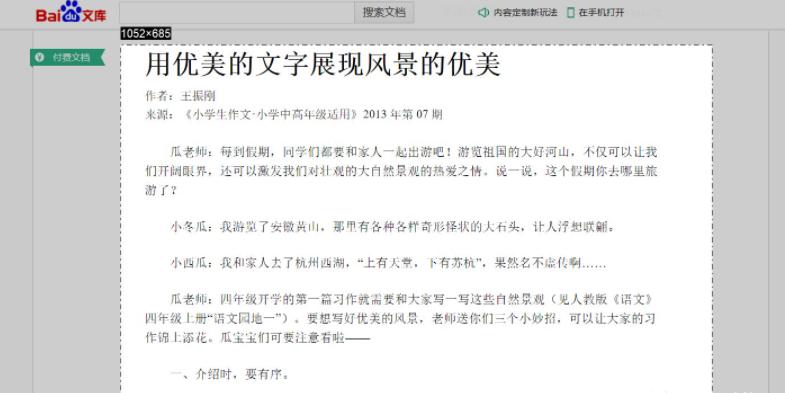
与手工录入相比,手写体表格数据自动录入系统不但输入速度快,而且可输入的数据进行各种计算以校对录入的正确性,从而在保证录入质量的同时极大的提高了工作效率。5. 其他场景。比如:SVHN数据集,车牌识别,CAPTCHA,PDF OCR,在自然环境下的OCR,Synth Text,MNIST等。一个对吃瓜群众来讲,较实用的场景:你在百度文库看见一份很有用的资料,但需要付费下载,这个时候你就可以截图后用OCR技术进行处理,如图所示:
03
关键技术
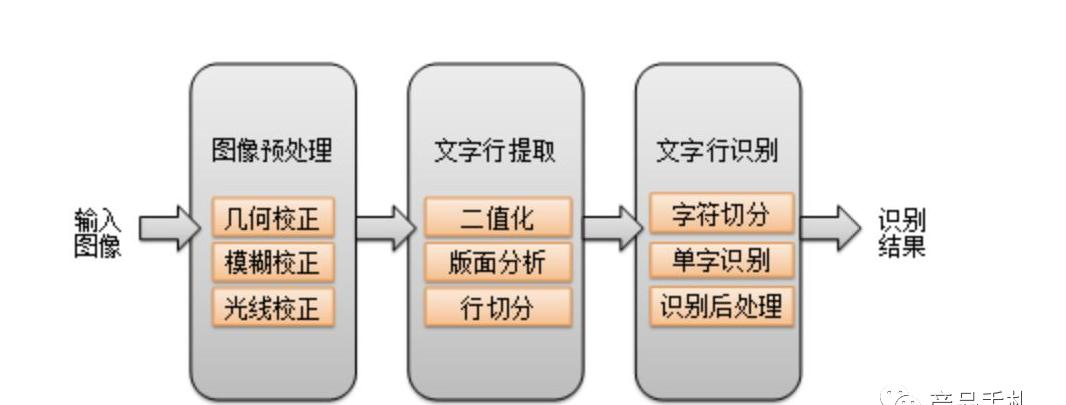
OCR技术主要用来自动识别图像中的文本内容,属于人工智能机器视觉识别领域的重要分支之一,需要把文本、卡证等载体上的文字通过图像识别手段转化为计算机能够识别的数据信息。广义的OCR识别技术,采用统计模式,处理流程较长,包括图像预处理、图像二值化、连通域分析、版面分析、行切分、字切分、单字符识别及后处理等技术步骤。典型的OCR识别技术环节,如下图:
 狭义的OCR识别技术,流程简单,涉及的核心流程:图像处理与文本识别,后处理等。识别文字前,需要对原始图片进行预处理,以便后续的特征提取和学习。这个过程通常包含:灰度化、二值化、降噪、倾斜矫正、文字切分等步骤。每个步骤涉及不同算法,以下图为例,进行各算法的演示。
狭义的OCR识别技术,流程简单,涉及的核心流程:图像处理与文本识别,后处理等。识别文字前,需要对原始图片进行预处理,以便后续的特征提取和学习。这个过程通常包含:灰度化、二值化、降噪、倾斜矫正、文字切分等步骤。每个步骤涉及不同算法,以下图为例,进行各算法的演示。
 其一、灰度化:将图片变为黑白色。其中,图片灰度化,在线网站见:http://www.txttool.com/t/?id=NDk5
其一、灰度化:将图片变为黑白色。其中,图片灰度化,在线网站见:http://www.txttool.com/t/?id=NDk5
 其二、二值化:一幅图像包括目标物体、背景还有噪声,要想从多值的数字图像中直接提取出目标物体,最常用的方法就是设定特定阈值T,用T将图像的数据分成两部分:大于T的像素群和小于T的像素群。这是研究灰度变换最特殊的方法,称为图像的二值化(binaryzation)。二值化的黑白图片不包含灰色,只有纯白和纯黑两种颜色。图像二值化,常见于软件比如:photoshop、美图秀秀等各种图像处理软件。
其二、二值化:一幅图像包括目标物体、背景还有噪声,要想从多值的数字图像中直接提取出目标物体,最常用的方法就是设定特定阈值T,用T将图像的数据分成两部分:大于T的像素群和小于T的像素群。这是研究灰度变换最特殊的方法,称为图像的二值化(binaryzation)。二值化的黑白图片不包含灰色,只有纯白和纯黑两种颜色。图像二值化,常见于软件比如:photoshop、美图秀秀等各种图像处理软件。
 图像降噪一般有均值滤波器、自适应维纳滤波器、中值滤波器、形态学噪声滤除器、小波去噪等。其四、倾斜矫正:对于用户而言,拍照的时候不可能绝对的水平,所以,我们需要通过程序将图像做旋转处理,来找一个认为最可能水平的位置,这样切出来的图,才有可能是最好的一个效果。倾斜矫正最常用的方法是霍夫变换,其原理是将图片进行膨胀处理,将断续的文字连成一条直线,便于直线检测。计算出直线的角度后就可以利用旋转算法,将倾斜图片矫正到水平位置。矫正效果如下图所示:
图像降噪一般有均值滤波器、自适应维纳滤波器、中值滤波器、形态学噪声滤除器、小波去噪等。其四、倾斜矫正:对于用户而言,拍照的时候不可能绝对的水平,所以,我们需要通过程序将图像做旋转处理,来找一个认为最可能水平的位置,这样切出来的图,才有可能是最好的一个效果。倾斜矫正最常用的方法是霍夫变换,其原理是将图片进行膨胀处理,将断续的文字连成一条直线,便于直线检测。计算出直线的角度后就可以利用旋转算法,将倾斜图片矫正到水平位置。矫正效果如下图所示:

其五、文字切分:对于一段多行文本来讲,文字切分包含了行切分与字符切分两个步骤,倾斜矫正是文字切分的前提。我们将倾斜矫正后的文字投影到 Y轴,并将所有值累加,这样就能得到一个在y轴上的直方图。
04
OCR技术竞争现状
(一)、国内的竞争格局:其一、国内头部互联网企业。比如百度、腾讯、阿里、网易、京东、美团、字节系等体量较大的互联网企业巨头。其二、国内较为头部的人工智能公司。常见的AI四小龙,商汤,云从,依图,旷世等均有涉及。另外,国内常见的语音厂商,如:科大讯飞、出门问问、云知声、speech、竹间智能等也有OCR技术的研究和实现。其三、起步较早的草根团队,比如:善于营销的云脉科技等。其四、背后大企业的伪OCR技术公司。这类公司在市面上比较多,不过背后的核心技术其实还是调用的前面三类企业,只是给普通消费者包了一层壳而已。比如:1. 创华OCR:套用微软yy过的OCR引擎和词库。2. 清华文通TH-OCR:国产(清华+文通) 国外企业Scansoft Nuance,值得支持,与汉王不同的是清华国际知名度比较好。微软向他买技术,满多印机、扫描仪也带它为ocr软件。3. 汉王:国产企业,资历很老,但水平一般。

(二)、国外的竞争格局:其一、常见的手机公司,常见的手机OS厂商Google,手机厂商:三星、苹果都有各自的OCR技术。非手机公司,比如亚马逊、微软等头部互联网企业也有自研的OCR技术。其二、不常见,但是体量很大的企业。1. ABBYY Finereader:国外4大OCR公司之一,众多打印机、扫描仪都自带它为ocr软件。安装程序约300MB,选择词库安装后约500MB。评价:功能齐全,众多软件中应该是第一。缺点:占cpu/内存大。有时会识别出一些不存在的字(和正确的字很相像,但不存在。造字?)友情提醒:Win有Corporate 和Professional (企业和专业)版,也有苹果Mac版,大家选自己要的。简介: 功能类似汉王屏幕摘抄、Mini Ocr是专门OCR识别屏幕截图用的。2. Nuance Omnipage Professional:3. Readiris Corporate:众多印机、扫描仪都自带它为ocr软件。安装程序约200MB,选择词库安装后约100MB。评价:功能可以,对表格的识别率ms比ABBYY FineReader高。没遇到FineReader的造字问题。缺点:没自带校对功能。一定用Asian版,没写Asian的不支持中文!4. Adobe Acrobat Pro简介:Adobe,nb公司啊!开玩笑,其实是买IRIS Readiris的技术。其实他的OCR技术也是给图片式PDF用的,识别后会在图片PDF的文字上附上识别文字,这样你可以拷贝pdf上的东西.缺点:没自带校对功能。友情提醒:不是免费的Reader,是Acrobat Pro或Acrobat Pro Extended版。
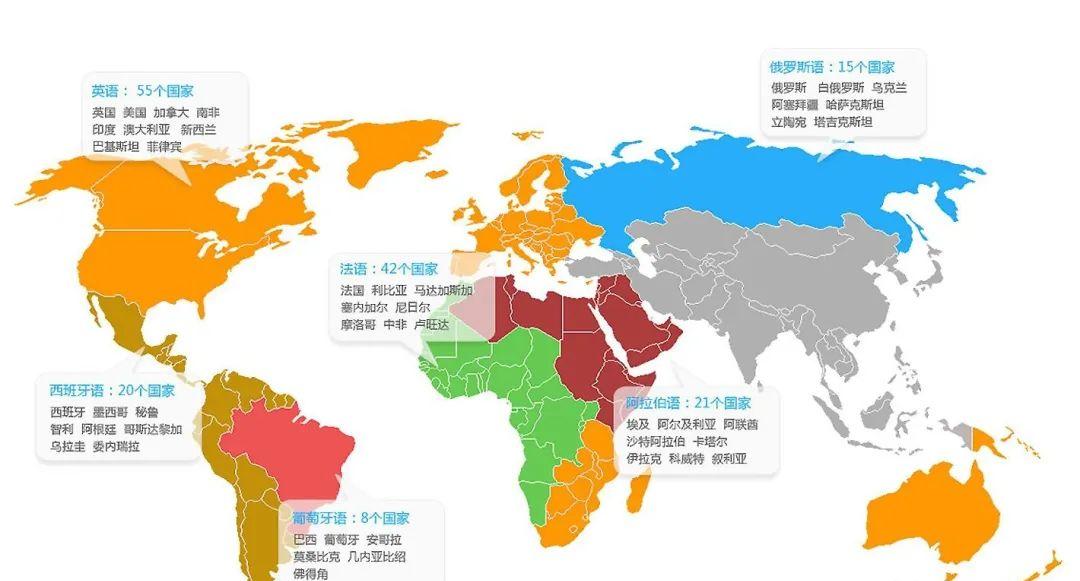
概括总结,国外OCR公司的一个特点是,支持的语种特别多。
05
OCR演变趋势
由中国信息通信研究院、中国人工智能产业发展联盟、腾讯公司相关部门联合起草人工智能白皮书指出,OCR 技术未来发展的三大方向包含:

其一,演变为一体化的端到端 OCR 模型。详细来说,构建一体化的端到端网络,对文字检测和识别进行训练,将成为 OCR 技术发展的重要趋势之一。端到端的网络设计不仅能减少重复计算,而且能提高特征的质量,促进任务性能改善。其二,扩展为兼具高性能与效率的 OCR。大量的 OCR 应用需要在资源受限的移动端设备运行,当前移动端 OCR 算法大多以牺牲一定算法精度来换取运行速度,针对移动设备设计兼顾性能和效率的轻量 OCR 模型将是未来发展的另一个重要方向。其三,从感知到认知的全智能 OCR。从感知到认知的智能 OCR 来说,OCR 技术通常从计算机视觉领域出发,未来与自然语言处理技术、知识图谱等更广领域的交叉融合,通过语义及知识的深度挖掘提升 OCR 性能是重要趋势。所以对智能手机领域而言,有几个趋势可以预测:兼具性能和效率的轻量级OCR模型是未来手机厂商必走之路。随着5G网络的普及加快,依靠云端计算的OCR模型会成为必然趋势。随着手机多种感知类设备的增强,OCR技术在应用场景上将成为基础服务,会结合智能翻译、文字转音频等技术联合出现。
06
致谢
以上,我对OCR核心技术进行了概述,并结合技术应用推广的现状,对OCR进行了介绍、总结、趋势预判。OCR技术已经取得了较大进步,关于它的研究已经成为视觉识别领域最前沿的内容之 一,反映了认知科学、人工智能、大数据的最新进展。互联网、物联网、移动互联网的普及为OCR提供了更广阔舞台。目前技术研究的主流趋势,集中在手写体识别、全字体识别、图文混排文档文字识别、视频图像文字识别等方面。在今后的发展过程中,OCR技术及其产品必将不断完善,应用领域也将更广泛,它的深入研究不仅可带动模式识别、人工智能等相关学科及分支学科的发展,而且可以拉近人与计算机的距离,促进人类科学的巨大进步,进而提升人类生活的便利性。

行将致远,终将致远!那些看似平凡的日复一日,会突然在某一天让人看到坚持的意义。